When evaluating the Ganglia Metrics for a given cluster with 3 executor nodes, which indicator would signal proper utilization of the VM's resources?
A nightly job ingests data into a Delta Lake table using the following code:
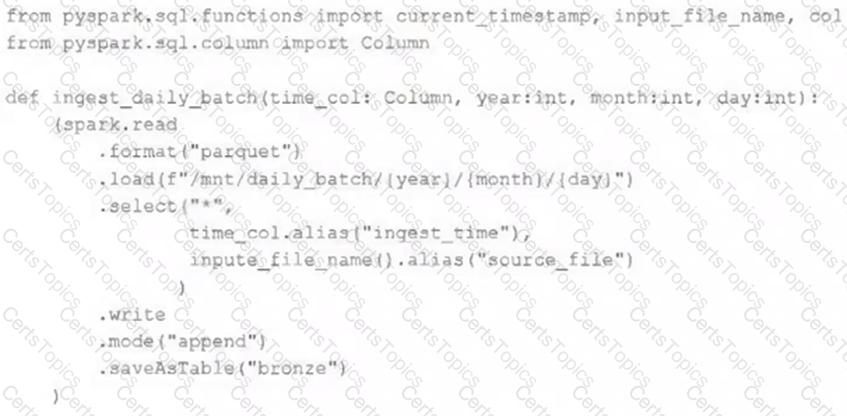
The next step in the pipeline requires a function that returns an object that can be used to manipulate new records that have not yet been processed to the next table in the pipeline.
Which code snippet completes this function definition?
def new_records():
return spark.readStream.table("bronze")
return spark.readStream.load("bronze")

return spark.read.option("readChangeFeed", "true").table ("bronze")

What is the first of a Databricks Python notebook when viewed in a text editor?
A production workload incrementally applies updates from an external Change Data Capture feed to a Delta Lake table as an always-on Structured Stream job. When data was initially migrated for this table, OPTIMIZE was executed and most data files were resized to 1 GB. Auto Optimize and Auto Compaction were both turned on for the streaming production job. Recent review of data files shows that most data files are under 64 MB, although each partition in the table contains at least 1 GB of data and the total table size is over 10 TB.
Which of the following likely explains these smaller file sizes?
Copyright © 2021-2026 CertsTopics. All Rights Reserved
