When running the command
sed -e "s/a/b/" /tmp/file >/tmp/file
While /tmp/file contains data, why is /tmp/file empty afterwards?
The file order is incorrect. The destination file must be mentioned before the command to ensure redirection.
The command sed did not match anything in that file therefore the output is empty.
When the shell establishes the redirection it overwrites the target file before the redirected command starts and opens it for reading.
Redirection for shell commands do not work using the > character. It only works using the | character instead.
The problem with the command
sed -e “s/a/b/” /tmp/file >/tmp/file
is that it tries to read and write from the same file, which results in overwriting the file before the command can process it. The shell sets up the redirection by opening the file /tmp/file for writing and truncating it to zero length. Then it executes the sed command, which tries to read from the same file, but finds it empty. Therefore, the output is also empty and the file remains empty. A possible solution is to use a temporary file for the output and then rename it to the original file name. For example:
sed -e “s/a/b/” /tmp/file >/tmp/file.tmp && mv /tmp/file.tmp /tmp/file
This way, the original file is not overwritten until the sed command finishes successfully. The other options are either incorrect or not applicable. The file order is correct, the sed command does match something in the file, and the > character is valid for redirection. The | character is used for piping, not redirection. References:
LPIC-1 Exam 101 Objectives, Topic 103: GNU and Unix Commands, 103.4 Use streams, pipes and redirects
LPIC-1 Linux Administrator 101-500 Exam FAQ, LPIC-1 Exam 101 Objectives, GNU and Unix Commands (Total Weight: 25)
: 6
The /etc/_______ file lists currently mounted devices.
mtab
The /etc/mtab file is a system-generated file that lists all the currently mounted devices and their mount options. It is updated automatically by the mount and umount commands. It can be used to check which devices are mounted and where, as well as their filesystem type and mount options. The /etc/mtab file has the same format as the /etc/fstab file, which is a user-edited file that lists the devices that should be mounted at boot time or on demand. References:
LPIC-1 Exam 101 Objectives, Topic 101: System Architecture, 101.1 Determine and configure hardware settings, Key Knowledge Areas, The following is a partial list of the used files, terms and utilities: /etc/mtab
LPIC-1 101-500 Exam Prep, Section 1: System Architecture, Lesson 1.1: Determine and Configure Hardware Settings, Video: 1.1.4 Mounting and Unmounting Filesystems, Transcript: The /etc/mtab file is a system-generated file that lists all the currently mounted devices and their mount options.
Which command is used in a Linux environment to create a new directory? (Specify ONLY the command without any path or parameters.)
mkdir
/usr/bin/mkdir
A
The mkdir command is used in a Linux environment to create a new directory. The mkdir command takes one or more arguments that specify the name and path of the directory to be created. For example, mkdir foo will create a directory named foo in the current working directory, while mkdir /home/bar will create a directory named bar in the /home directory. The mkdir command can also create multiple directories at once by using the -p option, which creates any missing parent directories along the path. For example, mkdir -p /tmp/a/b/c will create the directories /tmp, /tmp/a, /tmp/a/b and /tmp/a/b/c if they do not exist already. References:
LPIC-1 Exam 101 Objectives, Topic 103: GNU and Unix Commands, 103.3 Perform basic file management
LPIC-1 Linux Administrator 101-500 Exam FAQ, LPIC-1 Exam 101 Objectives, GNU and Unix Commands (Total Weight: 25)
Which variable defines the directories in which a Bash shell searches for executable commands?
BASHEXEC
BASHRC
PATH
EXECPATH
PATHRC
The PATH variable defines the directories in which a Bash shell searches for executable commands. The PATH variable is a colon-separated list of directories that the shell scans when a command is entered. For example, if the PATH variable is set to /usr/local/bin:/usr/bin:/bin, then the shell will look for the command in these three directories, in order. If the command is not found in any of these directories, the shell will report an error message. The other options are either invalid or do not perform the desired task. The BASHEXEC, EXECPATH and PATHRC variables are not valid Bash variables. The BASHRC variable is used to specify a file that is executed whenever a new interactive shell is started, but it does not affect the command search path. References:
LPIC-1 Exam 101 Objectives, Topic 103: GNU and Unix Commands, 103.1 Work on the command line
LPIC-1 Linux Administrator 101-500 Exam FAQ, LPIC-1 Exam 101 Objectives, GNU and Unix Commands (Total Weight: 25)
Which of the following commands will reduce all consecutive spaces down to a single space?
tr '\s' ' ' < a.txt > b.txt
tr -c ' ' < a.txt > b.txt
tr -d ' ' < a.txt > b.txt
tr -r ' ' '\n' < a.txt > b.txt
tr -s ' ' < a.txt > b.txt
The command that will reduce all consecutive spaces down to a single space is tr -s ’ ’ < a.txt > b.txt. This command uses the following options and syntax:
-s: Squeezes repeated characters listed in the first set with single occurrence.
’ ': Specifies a space character as the first set.
< a.txt: Redirects the input from a file named a.txt.
b.txt: Redirects the output to a file named b.txt.
The output of this command will be a new file called b.txt that contains the same text as a.txt, except that any sequence of multiple spaces will be replaced by a single space. For example, if the file a.txt contains the following text:
This is a text file with multiple spaces.
The file b.txt will contain the following text:
This is a text file with multiple spaces.
The other commands are incorrect for the following reasons:
A. tr ‘\s’ ’ ’ < a.txt > b.txt: This command will replace every whitespace character (\s) with a space character, which will not reduce the number of spaces, but rather convert tabs and newlines into spaces.
B. tr -c ’ ’ < a.txt > b.txt: This command will complement the first set, meaning that it will apply the operation to all characters that are not spaces. This will not affect the spaces at all, but rather squeeze all other characters.
C. tr -d ’ ’ < a.txt > b.txt: This command will delete all spaces from the input, which will not reduce them to a single space, but rather remove them completely.
D. tr -r ’ ’ ‘\n’ < a.txt > b.txt: This command will replace all spaces with newlines, which will not reduce the spaces, but rather create a new line for each word.
Which of the following commands will print the last 10 lines of a text file to the standard output?
cat -n 10 filename
dump -n 10 filename
head -n 10 filename
tail -n 10 filename
The tail command prints the last part of a file to the standard output. The -n option specifies the number of lines to print. Therefore, tail -n 10 filename will print the last 10 lines of the file named filename. The other commands are either invalid or do not perform the desired task. The cat command concatenates files and prints them to the standard output, but it does not have a -n option. The dump command is used to backup filesystems, not to print files. The head command prints the first part of a file, not the last part. References:
LPIC-1 Exam 101 Objectives, Topic 103: GNU and Unix Commands, 103.3 Perform basic file management
LPIC-1 Linux Administrator 101-500 Exam FAQ, LPIC-1 Exam 101 Objectives, GNU and Unix Commands (Total Weight: 25)
Which of the following files, located in the user home directory, is used to store the Bash history?
.bash_history
.bash_histfile
.history
.bashrc_history
.history_bash
The .bash_history file, located in the user home directory, is used to store the Bash history. The Bash history is a list of commands that the user has entered in the Bash shell. The .bash_history file is created when the user first starts a Bash session, and is updated when the user exits the session or runs the history command with the -a or -w option. The user can view the contents of the .bash_history file with the cat command, or use the history command to see the numbered list of commands. The user can also edit, delete, or clear the .bash_history file with various commands and options. The location and name of the history file can be changed by setting the HISTFILE environment variable to a different value. References:
[LPI Exam 101 Detailed Objectives], Topic 103: GNU and Unix Commands, Objective 103.1: Work on the command line, Weight: 4, Key Knowledge Areas: Use of history and HISTFILE.
Where is bash’s history stored?, Topic: Bash maintains the list of commands internally in memory while it’s running.
QUESTIONNO: 26
Which Bash environment variable defines in which file the user history is stored when exiting a Bash process? (Specify ONLY the variable name.)
Answer: HISTFILE
The HISTFILE environment variable defines in which file the user history is stored when exiting a Bash process. The user history is a list of commands that the user has entered in the Bash shell. By default, the HISTFILE variable is set to ~/.bash_history, which means that the history is stored in a hidden file called .bash_history in the user’s home directory. The user can change the value of the HISTFILE variable to store the history in a different file or location. For example, the following command will set the HISTFILE variable to ~/my_history:
export HISTFILE=~/my_history
This will cause the history to be stored in a file called my_history in the user’s home directory. The user can also unset the HISTFILE variable to disable the history saving feature. For example, the following command will unset the HISTFILE variable:
unset HISTFILE
This will prevent the history from being written to any file when the Bash process exits. The user can view the value of the HISTFILE variable by using the echo command. For example, the following command will display the value of the HISTFILE variable:
echo $HISTFILE
The output will be something like:
/home/user/.bash_history
Which grep command will print only the lines that do not end with a / in the file foo?
grep'/$' foo
grep '/#' foo
grep -v '/$' foo
grep -v '/#' foo
∗∗Thegrepcommandthatwillprintonlythelinesthatdonotendwitha/inthefilefooisgrep−v′/’ foo. This command uses the following options and pattern:
-v: Inverts the matching, meaning that it only outputs the lines that do not match the pattern. /:Matchesa/characterattheendofaline.The symbol represents the end of a line in regular expressions. foo: The name of the file to search.
The output of this command will show all the lines in the file foo that do not have a / as the last character. For example, if the file foo contains the following lines:
/home/user/ /var/log/messages /etc/passwd /usr/bin/
The output of the command will be:
/var/log/messages /etc/passwd
The other commands are incorrect for the following reasons:
grep ‘/$’ foo: This command will print only the lines that do end with a / in the file foo, which is the opposite of what is required.
grep ‘/#’ foo: This command will print only the lines that contain the string /# in the file foo, which is not related to the question.
grep -v ‘/#’ foo: This command will print only the lines that do not contain the string /# in the file foo, which is also not related to the question.
What is the effect of the egrep command when the -v option is used?
It enables color to highlight matching parts.
It only outputs non-matching lines.
It shows the command's version information.
It changes the output order showing the last matching line first.
The -v option for the egrep command activates the invert matching mode, which means that it only outputs the lines that do not match the given pattern or regular expression. This is useful for filtering out unwanted lines or finding exceptions in a file. For example, the following command will output all the lines in the file my_text that do not contain the word “Linux”:
egrep -v Linux my_text
The -v option can be combined with other options to modify the output format or behavior of the egrep command. For example, the -c option will count the number of non-matching lines instead of printing them, and the -i option will ignore the case of the pattern while matching. References:
[LPI Exam 101 Detailed Objectives], Topic 103: GNU and Unix Commands, Objective 103.7: Perform basic file management, Weight: 4, Key Knowledge Areas: Use of egrep to search for extended regular expressions in text output.
[Linux egrep Command with Examples], Topic: Invert Matching with egrep.
Which character, added to the end of a command, runs that command in the background as a child process of the current shell?
!
+
&
%
#
The character that, added to the end of a command, runs that command in the background as a child process of the current shell is the ampersand symbol (&). This means that the command will not block the shell and the user can enter other commands while the background command is running. The background command will also not receive any input from the keyboard or the terminal. The shell will print the job number and the process ID of the background command, and the user can use the jobs command to list the status of all background jobs in the current shell session. To bring a background job to the foreground, the user can use the fg command with the job number or the process ID. To terminate a background job, the user can use the kill command with the process ID.
The other characters are not valid or relevant for running a command in the background. The exclamation mark (!) is used to access the command history or to negate a condition. The plus sign (+) is used for arithmetic operations or to append text. The percent sign (%) is used for arithmetic operations or to refer to a job number. The hash sign (#) is used for comments or to specify a hexadecimal number.
In compliance with the FHS, in which of the directories are man pages found?
/usr/share/man
/opt/man
/usr/doc/
/var/pkg/man
/var/man
According to the Filesystem Hierarchy Standard (FHS), the directory /usr/share/man contains manual pages for user commands, system calls, library functions, and other documentation1. The other directories are either non-standard, deprecated, or used for different purposes. For example, /opt/man is used for manual pages for add-on application software packages1, /usr/doc/ is an old location for documentation files that is no longer used2, /var/pkg/man and /var/man are not defined by the FHS. References:
[LPI Linux Essentials - 1.6 Basic File Editing]
[LPI Linux Essentials - 1.7 Personalize and/or Localize Your Linux System]
[LPI Linux Essentials - 1.8 Basic Security and File Permissions]
Immediately after deleting 3 lines of text in vi and moving the cursor to a different line, which single character command will insert the deleted content below the current line?
i (lowercase)
P (uppercase)
p (lowercase)
U (uppercase)
u (lowercase)
The p command in vi inserts the content of the buffer below the current line. The buffer is where the deleted or yanked text is stored temporarily. The P command inserts the buffer above the current line. The i command enters the insert mode before the cursor position. The U command restores the current line to its original state. The u command undoes the last change made to the file. References:
[LPI Linux Essentials - 1.3 Basic Editing]
[LPI Linux Essentials - 1.4 I/O Redirection]
[LPI Linux Essentials - 1.5 Manage Simple Partitions and Filesystems]
What is the difference between the i and a command of the vi editor?
i (interactive) requires the user to explicitly switch between vi modes whereas a (automatic) switches modes automatically.
i (insert) inserts text before the current cursor position whereas a (append) inserts text after the cursor.
i (independent rows) starts every new line at the first character whereas a (aligned rows) keeps the indentation of the previous line.
i (interrupt) temporarily suspends editing of a file to the background whereas a (abort) terminates editing.
The i and a commands are two of the most commonly used commands in the vi editor to enter the insert mode. The insert mode allows the user to insert text into the file. The difference between the i and a commands is that the i command inserts text before the current cursor position, while the a command inserts text after the cursor position. For example, if the cursor is on the letter “e” in the word “editor”, then pressing i will allow the user to insert text before the “e”, while pressing a will allow the user to insert text after the “e”. The user can exit the insert mode by pressing the Esc key, which will return to the command mode. References:
Basic vi commands (cheat sheet)
VI Editor with Commands in Linux/Unix Tutorial
How to use Vi editor in Linux (with examples)
What does the? symbol within regular expressions represent?
Match the preceding qualifier one or more times.
Match the preceding qualifier zero or more times.
Match the preceding qualifier zero or one times.
Match a literal? character.
The ? symbol within regular expressions represents an optional match of the preceding qualifier. A qualifier is a character or a group of characters that can be repeated a certain number of times, such as , +, ?, {n}, {n,}, or {n,m}. The ? symbol means that the qualifier can occur zero or one times, but not more. For example, the regular expression colou?r matches both “color” and “colour”, but not “colouur” or “colr”. The ? symbol can also be used to make other qualifiers lazy, meaning that they will match the smallest possible number of characters, instead of the largest (greedy). For example, the regular expression a.?b matches the shortest string that starts with “a” and ends with “b”, such as “ab” or “a-b”, but not “a-b-c”. References:
[LPI Exam 101 Detailed Objectives], Topic 103: GNU and Unix Commands, Objective 103.7: Perform basic file management, Weight: 4, Key Knowledge Areas: Use of egrep to search for extended regular expressions in text output.
[Regular expression syntax cheat sheet], Topic: Quantifiers.
What is the maximum niceness value that a regular user can assign to a process with the nice command when executing a new process?
9
19
49
99
The maximum niceness value that a regular user can assign to a process with the nice command when executing a new process is 19. The niceness value is a user-space value that controls the priority of a process. The lower the niceness value, the higher the priority, and vice versa. The niceness value range is -20 to +19, where -20 is the highest priority and +19 is the lowest priority. The default niceness value is 0. The nice command can be used to run a new process with a modified niceness value. The syntax is: nice -n value command, where value is the niceness value and command is the process to run. For example, nice -n 10 sleep 60 will run the sleep command with a niceness value of 10 for 60 seconds. However, regular users can only increase the niceness value of their processes, not decrease it. This means that they can only lower the priority of their processes, not raise it. The minimum niceness value that a regular user can assign is 0, and the maximum is 19. Only the root user can assign a negative niceness value, which means raising the priority of a process. For example, nice -n -10 sleep 60 will run the sleep command with a niceness value of -10 for 60 seconds, but only if the user is root. The other options are not correct because:
A. 9 is not the maximum niceness value that a regular user can assign, but a valid niceness value within the range.
C. 49 is not a valid niceness value, as it exceeds the maximum of 19.
D. 99 is not a valid niceness value, as it exceeds the maximum of 19.
Regarding the command:
nice -5 /usr/bin/prog
Which of the following statements is correct?
/usr/bin/prog is executed with a nice level of -5.
/usr/bin/prog is executed with a nice level of 5.
/usr/bin/prog is executed with a priority of -5.
/usr/bin/prog is executed with a priority of 5.
The nice command is used to start a process with a modified scheduling priority. The scheduling priority is a value that determines how much CPU time a process will receive from the kernel. The lower the priority, the more CPU time a process will get. The priority is also known as the nice value, because a process with a high nice value is being nice to other processes by giving up CPU time. The nice value ranges from -20 to 19, with -20 being the highest priority and 19 being the lowest. By default, processes are started with a nice value of 0, which means normal priority.
The nice command takes an optional argument -n followed by a number, which specifies the increment or decrement of the nice value from the default value of 0. For example, the command:
nice -n 5 /usr/bin/prog
will start the /usr/bin/prog process with a nice value of 5, which means a lower priority than the default. Similarly, the command:
nice -n -5 /usr/bin/prog
will start the /usr/bin/prog process with a nice value of -5, which means a higher priority than the default. If the -n argument is omitted, the nice command will assume a default increment of 10. For example, the command:
nice /usr/bin/prog
will start the /usr/bin/prog process with a nice value of 10, which means a very low priority. Note that only the root user can start a process with a negative nice value, as this requires special privileges.
Therefore, the command:
nice -5 /usr/bin/prog
is equivalent to:
nice -n -5 /usr/bin/prog
and will start the /usr/bin/prog process with a nice value of -5, which means a higher priority than the default. This means that the correct answer is B. /usr/bin/prog is executed with a nice level of 5.
Which of the following commands prints a list of usernames (first column) and their primary group (fourth column) from the /etc/passwd file?
fmt -f 1,4 /etc/passwd
split -c 1,4 /etc/passwd
cut -d : -f 1,4 /etc/passwd
paste -f 1,4 /etc/passwd
The cut command is used to extract selected fields from each line of a file. The -d option specifies the delimiter that separates the fields, and the -f option specifies the fields to print. The /etc/passwd file contains information about the users on the system, and each field is separated by a colon (:). Therefore, cut -d : -f 1,4 /etc/passwd will print the first and fourth fields of each line, which are the username and the primary group ID respectively. The other commands are either invalid or do not perform the desired task. The fmt command is used to reformat paragraphs of text, but it does not have a -f option. The split command is used to split a file into smaller files, but it does not have a -c option. The paste command is used to merge lines of files, but it does not have a -f option. References:
LPIC-1 Exam 101 Objectives, Topic 103: GNU and Unix Commands, 103.3 Perform basic file management
LPIC-1 Linux Administrator 101-500 Exam FAQ, LPIC-1 Exam 101 Objectives, GNU and Unix Commands (Total Weight: 25)
Which of the following characters can be combined with a separator string in order to read from the current input source until the separator string, which is on a separate line and without any trailing spaces, is reached?
<<
<|
!<
&<
The << character is used to create a here document, which is a special type of redirection that reads input from the current source until a line containing only the delimiter (with no trailing blanks) is seen. The delimiter is specified after the << operator, and can be any string. For example, the following command will print everything between the << EOF and EOF lines:
cat << EOF This is a here document It can span multiple lines EOF
The output is:
This is a here document It can span multiple lines
The < character is used for normal input redirection, which reads data from a file or another command. The <| and !< characters are not valid redirection operators in Linux. The &< character is used to duplicate input file descriptors, which is an advanced topic not covered by the Linux Essentials exam. References:
[LPI Exam 101 Detailed Objectives], Topic 103: GNU and Unix Commands, Objective 103.4: Use streams, pipes and redirects, Weight: 4, Key Knowledge Areas: Redirecting standard input, standard output and standard error.
[LPI Linux Essentials Certification All-in-One Exam Guide], Chapter 5: Working with Files, Page 167, Using Here Documents.
QUESTIONNO: 16
Which of the following commands will NOT update the modify timestamp on the file /tmp/myfile.txt?
A. file /tmp/myfile.txt
B. echo "Hello" >/tmp/myfile.txt
C. sed -ie "s/1/2/" /tmp/myfile.txt
D. echo -n "Hello" >>/tmp/myfile.txt
E. touch/tmp/myfile.txt
Answer: A
The file command will not update the modify timestamp on the file /tmp/myfile.txt because it only reads the file content and determines its type. It does not write or change anything in the file.
The other commands will update the modify timestamp on the file /tmp/myfile.txt because they either overwrite the file content (B and C), append to the file content (D), or explicitly change the file timestamp (E).
Which of the following files, located in a user’s home directory, contains the Bash history?
.bashrc_history
.bash_histfile
.history
.bash_history
.history_bash
The correct answer is D, .bash_history. This file, located in a user’s home directory, contains the Bash history, which is a list of commands that the user has entered in the Bash shell. The syntax of the file is:
~/.bash_history
The ~ symbol represents the user’s home directory, which is usually /home/username. The / symbol is a directory separator that separates the components of a path. The . symbol at the beginning of the file name indicates that the file is hidden, which means that it is not normally displayed by the ls command or the file manager, unless the -a option or the show hidden files option is used. The bash_history is the name of the file that stores the Bash history.
The Bash history is maintained by the Bash shell while it is running, and it is written to the .bash_history file when the shell exits or when the history -a or -w options are used. The history command can be used to display, manipulate, or search the Bash history. The HISTFILE variable can be used to change the name or location of the .bash_history file. The HISTSIZE and HISTFILESIZE variables can be used to change the number of commands that are stored in the Bash history and the .bash_history file, respectively.
The other files are incorrect for the following reasons:
A, .bashrc_history: This file does not exist by default, and it is not used to store the Bash history. The .bashrc file is a configuration file that is executed by the Bash shell when it starts in interactive mode. It can contain commands, aliases, functions, variables, or other settings that affect the behavior of the shell. However, it is not used to store the history of the commands that the user has entered.
B, .bash_histfile: This file does not exist by default, and it is not used to store the Bash history. The .bash_histfile file is not a standard file name, and it is not recognized by the Bash shell. The Bash shell uses the .bash_history file to store the history of the commands that the user has entered, unless the HISTFILE variable is changed to a different file name.
C, .history: This file does not exist by default, and it is not used to store the Bash history. The .history file is not a standard file name, and it is not recognized by the Bash shell. The Bash shell uses the .bash_history file to store the history of the commands that the user has entered, unless the HISTFILE variable is changed to a different file name.
E, .history_bash: This file does not exist by default, and it is not used to store the Bash history. The .history_bash file is not a standard file name, and it is not recognized by the Bash shell. The Bash shell uses the .bash_history file to store the history of the commands that the user has entered, unless the HISTFILE variable is changed to a different file name.
What is true regarding the configuration of yum? (Choose two.)
Changes to the repository configuration become active after running yum confupdate
Changes to the yum configuration become active after restarting the yumd service
The configuration of package repositories can be divided into multiple files
Repository configurations can include variables such as $basearch or $releasever
In case /etc/yum.repos.d/ contains files, /etc/yum.conf is ignored
The configuration of yum can be divided into multiple files, and repository configurations can include variables such as $basearch or $releasever. The main configuration file for yum is /etc/yum.conf, which contains the global options for yum and can also define repositories in the [repository] sections. However, it is recommended to define individual repositories in separate files in the /etc/yum.repos.d/ directory, which can be easier to manage and maintain. Each file in this directory should have a .repo extension and contain one or more [repository] sections with the repository name, URL, and other options12. Repository configurations can use yum variables to dynamically set values for certain options, such as the baseurl or the enabled. Yum variables are enclosed in curly braces and start with a dollar sign, such as {$basearch} or {$releasever}. These variables are replaced by their actual values at runtime, based on the system architecture, the operating system version, or other factors. Some of the common yum variables are34:
$basearch: The base architecture of the system, such as x86_64, i386, or arm.
$releasever: The release version of the operating system, such as 7, 8, or 9.
$arch: The exact architecture of the system, such as x86_64, i686, or armv7hl.
$uuid: A unique identifier for the system, generated by the product-id plugin.
$YUM0-$YUM9: Custom variables that can be set by the user in the /etc/yum/vars/ directory or the /etc/yum.conf file.
The other options are false or irrelevant. There is no yum confupdate command or yumd service, and changes to the yum configuration become active immediately after saving the files. The /etc/yum.conf file is not ignored if the /etc/yum.repos.d/ directory contains files, but the repository options in the /etc/yum.conf file can be overridden by the options in the .repo files. References:
Linux Essentials - Linux Professional Institute Certification Programs1
Exam 101 Objectives - Linux Professional Institute2
How to Use Yum Variables to Enhance your Yum Experience - Red Hat …3
Yum Variables - CentOS4
Which parameter is missing in the command
ip link set _dev eth0
to activate the previously inactive network interface eth0? (Specify the parameter only without any command, path or additional options)
Up
Given the following input stream:
txt1.txt
atxt.txt
txtB.txt
Which of the following regular expressions turns this input stream into the following output stream?
txt1.bak.txt
atxt.bak.txt
txtB.bak.txt
s/^.txt/.bak/
s/txt/bak.txt/
s/txt$/bak.txt/
s/^txt$/.bak^/
s/[.txt]/.bak$1/
The correct answer is C, s/txt$/bak.txt/. This regular expression will turn the input stream into the desired output stream by using the s command, which is used to substitute or replace a pattern with another pattern. The syntax of the s command is:
s/pattern/replacement/
The pattern is the regular expression that matches the text to be replaced, and the replacement is the text that replaces the matched text. The / symbol is used as a delimiter to separate the pattern and the replacement, but other characters can be used as well.
The pattern in this regular expression is txt$, which means that it will match the string txt at the end of the line. The $ symbol is an anchor that matches the end of the line. The replacement in this regular expression is bak.txt, which means that it will replace the matched string with the string bak.txt.
Therefore, the command s/txt$/bak.txt/ will replace the string txt at the end of each line with the string bak.txt, resulting in the following output stream:
txt1.bak.txt atxt.bak.txt txtB.bak.txt
The other regular expressions are incorrect for the following reasons:
A, s/^.txt/.bak/: This regular expression will not work as expected, because it has several errors. First, the pattern in this regular expression is ^.txt, which means that it will match the string .txt at the beginning of the line. The ^ symbol is an anchor that matches the beginning of the line. However, none of the lines in the input stream start with .txt, so the pattern will not match anything. Second, the replacement in this regular expression is .bak, which means that it will replace the matched string with the string .bak. However, this will not produce the desired output, because it will not append the string .txt to the end of the line, but rather replace the existing string with .bak.
B, s/txt/bak.txt/: This regular expression will not work as expected, because it has several errors. First, the pattern in this regular expression is txt, which means that it will match the string txt anywhere in the line, not just at the end. This will cause unwanted replacements in the middle of the words, such as atxt and txtB. Second, the replacement in this regular expression is bak.txt, which means that it will replace the matched string with the string bak.txt. However, this will not produce the desired output, because it will not preserve the original string, but rather replace it with bak.txt.
D, s/txt$/.bak/: This regular expression will not work as expected, because it has several errors. First, the pattern in this regular expression is ^txt$, which means that it will match the string txt only if it is the entire line. The ^ and $ symbols are anchors that match the beginning and the end of the line, respectively. However, none of the lines in the input stream are exactly txt, so the pattern will not match anything. Second, the replacement in this regular expression is .bak^, which means that it will replace the matched string with the string .bak^. However, this will not produce the desired output, because it will not append the string .txt to the end of the line, but rather replace the existing string with .bak^, which is not a valid file name.
E, s/[.txt]/.bak$1/: This regular expression will not work as expected, because it has several errors. First, the pattern in this regular expression is [.txt], which means that it will match any one of the characters inside the brackets, which are ., t, and x. This will cause unwanted replacements of single characters, such as the dot in the file extension or the letter t in the word atxt. Second, the replacement in this regular expression is .bak$1, which means that it will replace the matched character with the string .bak followed by the first backreference. A backreference is a way to refer to a part of the pattern that was captured by parentheses. However, there are no parentheses in the pattern, so the backreference $1 is invalid and will not work. Third, the replacement in this regular expression will not produce the desired output, because it will not append the string .txt to the end of the line, but rather replace the existing character with .bak$1, which is not a valid file name.
Given the following routing table:

How would an outgoing packet to the destination 192 168 2 150 be handled?
It would be passed to the default router 192 168 178 1 onwIan0.
It would be directly transmitted on the device eth0
It would be passed to the default router 255 255 255 0 on eth0
It would be passed to the router 192 168.1.1 oneth0
It would be directly transmitted on the device wlan0.
Which command uninstalls a package but keeps its configuration files in case the package is re-installed?
dpkg –s pkgname
dpkg –L pkgname
dpkg –P pkgname
dpkg –v pkgname
dpkg –r pkgname
The command that uninstalls a package but keeps its configuration files in case the package is re-installed is dpkg -r pkgname. The dpkg command is the low-level tool for installing, building, removing, and managing Debian packages. The -r or --remove option removes an installed package from the system, but it does not delete the configuration files and other data that belong to the package. This way, if the package is re-installed later, the previous settings are preserved. The dpkg command is part of the 101.1 Determine and configure hardware settings topic of the LPI Linux Essentials certification program12.
The other options are either invalid or do not perform the desired task. The dpkg -s pkgname command shows the status of an installed package, but it does not uninstall it. The dpkg -L pkgname command lists the files that belong to an installed package, but it does not uninstall it. The dpkg -P pkgname command purges an installed or removed package, which means it deletes the configuration files and other data that belong to the package. The dpkg -v pkgname command shows the version of an installed package, but it does not uninstall it.
What is contained on the EFI System Partition?
The Linux root file system
The first stage boot loader
The default swap space file
The Linux default shell binaries
The user home directories
The EFI System Partition (ESP) is a special partition on a disk that contains the UEFI boot loaders, applications and drivers for the installed operating systems. The UEFI firmware will load these files from the ESP when the system boots. The ESP is mandatory for UEFI boot and it is usually formatted with a FAT file system. The ESP is part of the 101.1 Determine and configure hardware settings topic of the LPI Linux Essentials certification program12.
The other options are false or irrelevant. The Linux root file system is not contained on the ESP, it is usually on a separate partition with a Linux file system, such as ext4 or btrfs. The default swap space file is not contained on the ESP, it is usually on a swap partition or a swap file on the Linux root file system. The Linux default shell binaries are not contained on the ESP, they are usually on the /bin directory of the Linux root file system. The user home directories are not contained on the ESP, they are usually on the /home directory of the Linux root file system or on a separate partition. References:
Linux Essentials - Linux Professional Institute Certification Programs1
Exam 101 Objectives - Linux Professional Institute2
EFI system partition - ArchWiki3
/boot/efi Linux partition: What is, usage recommendations
Which of the following tasks are handled by a display manager like XDM or KDM? (Choose TWO correct answers.)
Configure additional devices like new monitors or projectors when they are attached
Start and prepare the desktop environment for the user
Create an X11 configuration file for the current graphic devices and monitors
Lock the screen when the user was inactive for a configurable amount of time
Handle the login of a user
How do shadow passwords improve the password security in comparison to standard non-shadow passwords'?
Regular users do not have access to the password hashes of shadow passwords
Every shadow password is valid for 45 days and must be changed afterwards
The system's host key is used to encrypt all shadow passwords.
Shadow passwords are always combined with a public key that has to match the user's private key
Shadow passwords are stored in plain text and can be checked for weak passwords
What is true regarding the statement beginning with #! that is found in the first line of a script? (Choose TWO correct answers.)
It prevents the script from being executed until the \ is removed
It triggers the installation of the scripts interpreter
It specifies the path and the arguments of the interpreter used to run the script
It defines the character encoding of the script
It is a comment that is ignored by the script interpreter
Which file contains the date of the last change of a user's password?
/etc/gshadow
/etc/passwd
/etc/pwdlog
/var/log/shadow
/etc/shadow
What command is used to add OpenSSH private keys to a running ssh-agent instance? (Specify the command name only without any path.)
ssh-add
What is true regarding public and pnvate SSH keys? (Choose TWO correct answers.)
For each user account, there is exactly one key pair that can be used to log into that account
The private key must never be revealed to anyone
Several different public keys may be generated for the same private key
To maintain the private key's confidentiality, the SSH key pair must be created by its owner
To allow remote logins, the user's private key must be copied to the remote server
When considering the use of hard links, what are valid reasons not to use hard links?
Hard links are not available on all Linux systems because traditional filesystems, such as ext4, do not support them
Each hard link has individual ownership, permissions and ACLs which can lead to unintended disclosure of file content
Hard links are specific to one filesystem and cannot point to files on another filesystem
If users other than root should be able to create hard links, suln has to be installed and configured
When a hard linked file is changed, a copy of the file is created and consumes additional space
The only valid reason not to use hard links is that they are specific to one filesystem and cannot point to files on another filesystem. This means that if you want to link files across different partitions or devices, you cannot use hard links. You have to use symbolic links instead, which are pointers to file names rather than inodes. The other options are either false or irrelevant. Hard links are available on most Linux systems and traditional filesystems, such as ext4, do support them1. Each hard link shares the same ownership, permissions and ACLs as the original file, which can be an advantage or a disadvantage depending on the use case2. There is no such thing as suln, and users other than root can create hard links as long as they have write permission on the directory where the link is created3. When a hard linked file is changed, no copy of the file is created and no additional space is consumed. The changes are reflected on all the hard links pointing to the same inode4. References:
Linux Essentials - Linux Professional Institute Certification Programs1
Exam 101 Objectives - Linux Professional Institute2
Hard links and soft links in Linux explained | Enable Sysadmin3
Hard Link in Linux: Everything Important You Need to Know4
Consider the following directory:
drwxrwxr-x 2 root sales 4096 Jan 1 15:21 sales
Which command ensures new files created within the directory sales are owned by the group sales? (Choose two.)
chmod g+s sales
setpol –R newgroup=sales sales
chgrp –p sales sales
chown --persistent *.sales sales
chmod 2775 sales
The command chmod g+s sales sets the setgid bit on the directory sales, which means that any new file or subdirectory created within sales will inherit the group ownership of the directory. The command chmod 2775 sales does the same thing, but also sets the permissions of the directory to rwxrwxr-x, which means that the owner, group, and others can read, write, and execute files in the directory. Both commands ensure that new files created within the directory sales are owned by the group sales. The other commands are either invalid or do not affect the group ownership of new files. References:
Linux Essentials - Linux Professional Institute Certification Programs1
Exam 101 Objectives - Linux Professional Institute
Which of the following apt-get subcommands installs the newest versions of all currently installed packages?
auto-update
dist-upgrade
full-upgrade
install
update
The apt-get subcommand that installs the newest versions of all currently installed packages is dist-upgrade. The dist-upgrade subcommand performs the same function as the upgrade subcommand, which is to install the latest versions of the packages that are already installed on the system, but it also intelligently handles the dependencies and removes the obsolete packages if necessary. The dist-upgrade subcommand is useful when upgrading the entire system to a new release or distribution12.
The other options are either invalid or do not perform the desired task. The auto-update subcommand does not exist, and the update subcommand only updates the list of available packages from the repositories, but does not install any packages. The full-upgrade subcommand is an alias for the dist-upgrade subcommand, so it performs the same function, but it is not the standard name for the subcommand. The install subcommand installs new packages or specific versions of packages, but it does not upgrade all the currently installed packages. References:
Linux Essentials - Linux Professional Institute Certification Programs1
Exam 101 Objectives - Linux Professional Institute2
APT-GET Command in Linux {Detailed Tutorial With Examples} - phoenixNAP3
How do I get help on apt-get’s install subcommand?
APT Cheat Sheet | Packagecloud Blog
What is true about the file .profile in a user's home directory?
It must be executable
It must call the binary of the login shell
It must use a valid shell script syntax
It must start with a shebang
It must be readable for its owner only
Which of the following keywords can be used in the die /etc/resolv.conf? (Choose TWO correct answers.)
substitute
lookup
search
nameserver
method
During a system boot cycle, what is the program that is run after the BIOS completes its tasks?
The bootloader
The inetd program
The init program
The kernel
The program that is run after the BIOS completes its tasks is the bootloader12. The bootloader is a small program that loads the operating system into memory and executes it. The bootloader can be located in the Master Boot Record (MBR) of the first hard disk or the boot sector of a partition for BIOS systems, or in an .efi file on the EFI System Partition for UEFI systems12. The bootloader can also display a menu to allow the user to choose from different operating systems or kernel versions to boot12.
The other options in the question are not correct because:
B. The inetd program: This is a program that listens for incoming network connections and launches the appropriate service for them. It is not involved in the boot process3.
C. The init program: This is a program that is executed by the kernel as the first user-space process. It is responsible for starting and managing other processes and services. It is not run by the BIOS.
D. The kernel: This is the core of the operating system that controls everything in the system. It is loaded and executed by the bootloader, not by the BIOS.
Which of the following commands brings a system running SysV init into a state in which it is safe to perform maintenance tasks? (Choose TWO correct answers.)
shutdown -R 1 now
shutdown -single now
init 1
telinit 1
runlevel 1
The commands init 1 and telinit 1 both bring a system running SysV init into a state in which it is safe to perform maintenance tasks. This state is also known as single-user mode or runlevel 1, where only the root user can log in and no network services are running. The command shutdown -R 1 now is incorrect, because it reboots the system instead of entering single-user mode. The command shutdown -single now is invalid, because the -single option does not exist for the shutdown command. The command runlevel 1 is also invalid, because runlevel is a command that displays the current and previous runlevels, not a command that changes the runlevel. References:
1: SysVinit - ArchWiki
2: Linux: How to write a System V init script to start, stop, and restart my own application or service - nixCraft
3: sysvinit - Gentoo wiki
Which of the following are init systems used within Linux systems? (Choose THREE correct answers.)
startd
systemd
Upstart
SysInit
SysV init
systemd, Upstart, and SysV init are all init systems used within Linux systems. An init system is the first process executed by the kernel at boot time, which has a process ID (PID) of 1, and is responsible for starting and managing all other processes on the system. Different init systems have different features, advantages, and disadvantages. Some of the most common init systems are:
systemd: A relatively new and modern init system that aims to provide a unified and efficient way of managing system and service states. It is compatible with SysV and LSB init scripts, and supports features such as parallel processing, socket activation, logging, job scheduling, and more. It is the default init system for many popular Linux distributions, such as Fedora, Debian, Ubuntu, Arch Linux, and others12.
Upstart: An event-based init system developed by Ubuntu as a replacement for SysV init. It starts and stops system tasks and processes based on events, such as hardware changes, network availability, filesystem mounting, etc. It is a hybrid init system that uses both SysV and systemd scripts, and supports features such as parallel processing, dependency tracking, logging, and more. It is the default init system for some older versions of Ubuntu, and some other Linux distributions, such as Linux Mint and Chrome OS12.
SysV init: A mature and traditional init system that follows the System V (SysV) design of Unix operating systems. It uses a series of runlevels to define the state of the system, and executes scripts in the /etc/rc.d or /etc/init.d directories according to the current runlevel. It is simple and stable, but lacks some features of modern init systems, such as parallel processing, event handling, dependency tracking, etc. It is still used by some Linux distributions, such as Slackware, Gentoo, and others12.
Which SysV init configuration file should be modified to disable the ctrl-alt-delete key combination?
/etc/keys
/proc/keys
/etc/inittab
/proc/inittab
/etc/reboot
The /etc/inittab file is used by the SysV init system to configure the behavior of different runlevels and the actions to be taken when certain events occur. One of the events that can be configured is the ctrl-alt-delete key combination, which by default triggers a system reboot. To disable this feature, the /etc/inittab file should be modified to comment out or remove the line that starts with ca::ctrlaltdel:. References: LPI Linux Essentials - 1.101.2, LPI Linux Administrator - 101.1
You are having some trouble with a disk partition and you need to do maintenance on this partition but your users home directories are on it and several are logged in. Which command would disconnect the users and allow you to safely execute maintenance tasks?
telinit 1
shutdown -r now
killall -9 inetd
/bin/netstop --maint
/etc/rc.d/init.d/network stop
The command that would disconnect the users and allow you to safely execute maintenance tasks on a disk partition is telinit 112. The telinit command is used to change the runlevel of the system, which is a mode of operation that defines what processes and services are running3. The runlevel 1, also known as single-user mode, is a mode that allows only the root user to log in, and disables all network services and graphical interfaces4. This mode is useful for performing system maintenance and recovery tasks, such as repairing a disk partition5.
The other options in the question are not correct because:
B. shutdown -r now: This command would reboot the system immediately, without disconnecting the users gracefully or allowing you to do any maintenance tasks.
C. killall -9 inetd: This command would kill the inetd process, which is a daemon that manages network services. This would not disconnect the users who are already logged in, and it would not stop other processes that might interfere with the maintenance tasks.
D. /bin/netstop --maint: There is no such command in Linux.
E. /etc/rc.d/init.d/network stop: This command would stop the network service, which would disconnect the users who are logged in remotely, but not the ones who are logged in locally. It would also not stop other processes that might interfere with the maintenance tasks.
Which of the following statements is correct when talking about /proc/?
All changes to files in /proc/ are stored in /etc/proc.d/ and restored on reboot.
All files within /proc/ are read-only and their contents cannot be changed.
All changes to files in /proc/ are immediately recognized by the kernel.
All files within /proc/ are only readable by the root user.
The /proc/ directory is a virtual filesystem that provides a view of the kernel’s data structures and parameters. It contains information about processes, hardware, memory, modules, and other aspects of the system. The files in /proc/ are not stored on disk, but are generated on the fly by the kernel when they are accessed. Therefore, any changes to files in /proc/ are immediately recognized by the kernel and affect its behavior. For example, writing a value to /proc/sys/kernel/hostname will change the system’s hostname without rebooting. The files in /proc/ are not all read-only; some of them can be modified by the root user or by processes with the appropriate permissions. The files in /proc/ are readable by any user, unless restricted by the kernel or by the mount options. References: LPI Linux Essentials - 1.101.2, LPI Linux Administrator - 102.3
The USB device filesystem can be found under /proc/______/usb/. (Please fill in the blank with the single word only)
bus
The USB device filesystem can be found under /proc/bus/usb/1. This is a virtual filesystem that provides information about the USB devices and buses connected to the system12. It contains files and directories that correspond to the USB host controllers, hubs, and devices12. For example, the following output shows the contents of /proc/bus/usb/ on a system with one USB host controller and two USB devices:
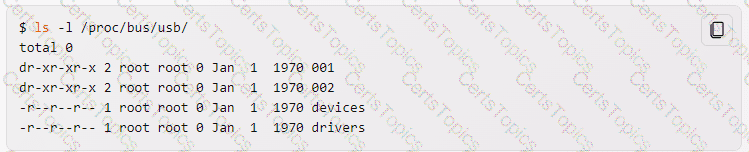
The directories 001 and 002 represent the USB buses, and each contain files that represent the USB devices on that bus. The file devices contains a summary of all the USB devices and their configurations. The file drivers contains a list of the USB drivers and the devices they are bound to12.
The /proc/bus/usb/ filesystem is deprecated and should not be used anymore3. It has been replaced by the /sys/bus/usb/ filesystem, which is a sysfs mount that provides more detailed and structured information about the USB devices and buses3 .
Which command will display messages from the kernel that were output during the normal boot sequence?
dmesg
The command dmesg will display messages from the kernel that were output during the normal boot sequence. The dmesg command reads the kernel ring buffer, which is a data structure that stores the most recent messages generated by the kernel. The dmesg command can also be used to display messages from the kernel that were output after the boot sequence, such as hardware events, driver messages, or system errors. The dmesg command has various options to filter, format, or save the output. For example, dmesg -T will display human-readable timestamps for each message, and dmesg -w will display the messages in real time as they occur. References:
1: How to view all boot messages in Linux after booting? - Super User
2: dmesg(1) - Linux manual page
3: Kernel ring buffer - Wikipedia
Which of the following commands reboots the system when using SysV init? (Choose TWO correct answers.)
shutdown -r now
shutdown -r "rebooting"
telinit 6
telinit 0
shutdown -k now "rebooting"
The shutdown command is used to bring the system down in a safe and controlled way. It can take various options and arguments, such as the time of shutdown, the message to broadcast to users, the halt or reboot mode, etc. The option -r instructs the shutdown command to reboot the system after shutting down. The argument now means to shut down immediately. Therefore, shutdown -r now will reboot the system without delay. The telinit command is used to change the run level of the system. It takes a single argument that specifies the new run level. The run level 6 is reserved for rebooting the system. Therefore, telinit 6 will also reboot the system. The other options are either incorrect or irrelevant. shutdown -r “rebooting” will also reboot the system, but with a delay of one minute and a message to the users. telinit 0 will halt the system, not reboot it. shutdown -k now “rebooting” will only send a warning message to the users, but not actually shut down or reboot the system. References: LPI Linux Essentials - 1.101.2, LPI Linux Administrator - 101.3
What is the first program that is usually started, at boot time, by the Linux kernel when using SysV init?
/lib/init.so
/sbin/init
/etc/rc.d/rcinit
/proc/sys/kernel/init
/boot/init
The first program that is usually started, at boot time, by the Linux kernel when using SysV init is /sbin/init. This program is responsible for reading the /etc/inittab file and executing the appropriate scripts and programs for each runlevel. The other options are not valid programs that are started by the kernel. /lib/init.so is a shared library that is used by some init programs, but not by SysV init. /etc/rc.d/rcinit is a script that is run by init, not by the kernel. /proc/sys/kernel/init is a kernel parameter that can be used to specify a different init program, but the default value is /sbin/init. /boot/init is not a standard location for an init program, and it is unlikely that the kernel would find it there. References:
1: SysVinit - ArchWiki
2: Linux: How to write a System V init script to start, stop, and restart my own application or service - nixCraft
3: sysvinit - Gentoo wiki
Which of the following information is stored within the BIOS? (Choose TWO correct answers.)
Boot device order
Linux kernel version
Timezone
Hardware configuration
The system's hostname
The BIOS (Basic Input/Output System) is a firmware that is stored in a ROM chip on the motherboard and is responsible for initializing the hardware and loading the bootloader. The BIOS has a setup utility that allows the user to configure various settings, such as the boot device order, the hardware configuration, the system date and time, the security options, etc. The BIOS does not store information about the Linux kernel version, the time zone, or the system’s hostname, as these are part of the operating system and are not relevant for the BIOS. References: LPI Linux Essentials - 1.101.1, LPI Linux Administrator - 102.1
The system is having trouble and the engineer wants to bypass the usual /sbin/init start up and run /bin/sh. What is the usual way to pass this change to the kernel from your boot loader?
Start in runlevel 1.
Pass init=/bin/sh on the kernel parameter line.
Pass /bin/sh on the kernel parameter line.
Pass start=/bin/sh on the kernel parameter line.
The usual way to pass this change to the kernel from the boot loader is to pass init=/bin/sh on the kernel parameter line12. The init kernel parameter is used to specify the program that is run as the first process after the kernel is loaded3. By default, this program is /sbin/init, which is responsible for starting and managing other processes and services4. However, by passing init=/bin/sh, the kernel will run /bin/sh instead, which is a shell program that allows the user to execute commands interactively or from a script5. This way, the user can bypass the usual initialization process and run /bin/sh as the root user, which can be useful for troubleshooting or recovery purposes12.
The other options in the question are not correct because:
A. Start in runlevel 1: This option would not bypass the /sbin/init program, but rather instruct it to start the system in single-user mode, which is a mode that allows only the root user to log in, and disables all network services and graphical interfaces. To start in runlevel 1, the user would need to pass single or 1 on the kernel parameter line, not init=/bin/sh.
C. Pass /bin/sh on the kernel parameter line: This option would not work, because the kernel would not recognize /bin/sh as a valid parameter and would ignore it. The kernel only accepts parameters that have a specific format, such as name=value or name.flag3. To specify the init program, the user would need to use the init= prefix, as in init=/bin/sh3.
D. Pass start=/bin/sh on the kernel parameter line: This option would also not work, because the kernel does not have a start parameter. The user would need to use the init parameter, as in init=/bin/sh3.
During a system boot cycle, what program is executed after the BIOS completes its tasks?
The bootloader
The inetd program
The init program
The kernel
The bootloader is a program that is executed by the BIOS after it completes its tasks of initializing the hardware and performing the POST (Power-On Self Test). The bootloader is responsible for loading the kernel and other necessary files into memory and passing control to the kernel. The bootloader can be either installed in the Master Boot Record (MBR) of the disk or in a separate partition. Some examples of bootloaders are GRUB, LILO, and SYSLINUX. References: LPI Linux Essentials - 1.101.1, LPI Linux Administrator - 102.1
The message "Hard Disk Error" is displayed on the screen during Stage 1 of the GRUB boot process. What does this indicate?
The kernel was unable to execute /bin/init
The next Stage cannot be read from the hard disk because GRUB was unable to determine the size and geometry of the disk
One or more of the filesystems on the hard disk has errors and a filesystem check should be run
The BIOS was unable to read the necessary data from the Master Boot Record to begin the boot process
The GRUB boot process consists of three stages1:
Stage 1: This stage is located in the Master Boot Record (MBR) of the first hard disk or the boot sector of a partition. Its main function is to load either Stage 1.5 or Stage 22.
Stage 1.5: This stage is located in the first 30 KB of hard disk immediately following the MBR or in the boot sector of a partition. It contains the code to access the file system that contains the GRUB configuration file. Its main function is to load Stage 22.
Stage 2: This stage is located in an ordinary file system, usually in the /boot/grub directory. It contains the code to display the GRUB menu and to load the kernel and initrd images. It can also load additional modules to support other file systems or features2.
The message “Hard Disk Error” is displayed on the screen during Stage 1 of the GRUB boot process. This indicates that the next Stage (either Stage 1.5 or Stage 2) cannot be read from the hard disk because GRUB was unable to determine the size and geometry of the disk3. This could occur because the BIOS translated geometry has been changed by the user or the disk is moved to another machine or controller after installation, or GRUB was not installed using itself (if it was, the Stage 2 version of this error would have been seen during that process and it would not have completed the install)3.
The other options in the question are not correct because:
A. The kernel was unable to execute /bin/init: This error would occur in Stage 2, after the kernel and initrd images are loaded, not in Stage 14.
C. One or more of the filesystems on the hard disk has errors and a filesystem check should be run: This error would also occur in Stage 2, when GRUB tries to access the file system that contains the GRUB configuration file, not in Stage 15.
D. The BIOS was unable to read the necessary data from the Master Boot Record to begin the boot process: This error would prevent GRUB from starting at all, not in Stage 16.
What information can the lspci command display about the system hardware? (Choose THREE correct answers.)
Device IRQ settings
PCI bus speed
System battery type
Device vendor identification
Ethernet MAC address
The lspci command can display information about the system hardware, such as:
Device IRQ settings1: The lspci command can show the interrupt request (IRQ) number assigned to each device by using the -v option. The IRQ number indicates how the device communicates with the CPU.
PCI bus speed2: The lspci command can show the speed of the PCI bus by using the -vv option. The speed is expressed in megahertz (MHz) or gigahertz (GHz) and indicates how fast the data can be transferred between the device and the bus.
Device vendor identification3: The lspci command can show the name and identification number of the device vendor by using the -n or -nn option. The vendor identification helps to identify the manufacturer and model of the device.
Which file in the /proc filesystem lists parameters passed from the bootloader to the kernel? (Specify the file name only without any path.)
cmdline
The file in the /proc filesystem that lists the parameters passed from the bootloader to the kernel is /proc/cmdline. This file contains a single line of text that shows the command line arguments that were used to boot the kernel. These arguments can include various options, such as the root device, the init process, the console device, and more. The /proc/cmdline file is read-only and cannot be modified at runtime. The parameters in this file are determined by the bootloader configuration, such as GRUB or LILO, and can be changed by editing the corresponding files12.
Which of the following kernel parameters instructs the kernel to suppress most boot messages?
silent
verbose=0
nomesg
quiet
The quiet kernel parameter instructs the kernel to suppress most boot messages, except for critical errors12. The quiet parameter can be added to the GRUB_CMDLINE_LINUX_DEFAULT variable in the /etc/default/grub file and then run sudo update-grub to apply the changes3. The quiet parameter can also be used in combination with other parameters, such as splash, to enable a graphical boot screen4.
The other options in the question are not valid or do not have the same functionality as the quiet parameter:
silent: There is no such kernel parameter in Linux.
verbose=0: This parameter is used to set the verbosity level of the kernel messages, but it does not suppress them completely. The valid values for this parameter are from 0 (quiet) to 7 (debug)5.
nomesg: This parameter is used to disable all kernel messages on the console, including the emergency ones. This parameter is not recommended for normal use, as it can hide critical errors and prevent troubleshooting.
Which run levels should never be declared as the default run level when using SysV init? (Choose TWO correct answers.)
0
1
3
5
6
Run levels are predefined modes of operation in the SysV init system that determine which processes and services are started or stopped. The default run level is the one that the system enters after booting. It is usually specified in the /etc/inittab file with a line like id:5:initdefault:. The run levels 0 and 6 should never be declared as the default run level because they are used to halt and reboot the system, respectively. If they are set as the default, the system will enter an endless loop of shutting down and restarting. The other run levels (1-5) have different meanings depending on the distribution, but they usually correspond to single-user mode, multi-user mode, network mode, graphical mode, etc. References: LPI Linux Essentials - 1.101.2, LPI Linux Administrator - 101.3
Following the Filesystem Hierarchy Standard (FHS), where should binaries that have been compiled by the system administrator be placed in order to be made available to all users on the system?
/usr/local/bin/
According to the Filesystem Hierarchy Standard (FHS), the /usr/local/ directory is for use by the system administrator when installing software locally. It needs to be safe from being overwritten when the system software is updated. The /usr/local/bin/ directory is for local binaries that are not managed by the distribution package manager. These binaries should be accessible to all users on the system. Therefore, binaries that have been compiled by the system administrator should be placed in /usr/local/bin/ to follow the FHS. References:
Filesystem Hierarchy Standard - Linux Foundation
Filesystem Hierarchy Standard (FHS) | Linux# - Geek University
Which of the following commands instructs SysVinit to reload its configuration file?
reinit
initreload
telinit 7
telinit q
init reinit
SysVinit is a program for Linux and Unix-based systems that initializes the system and spawns all other processes. It runs as a daemon and has PID 1. The boot loader starts the kernel and the kernel starts SysVinit. A Linux or Unix based system can be started up into various runlevels, which are modes of operation that define what services and processes are running. The /etc/inittab file is the configuration file for SysVinit, which defines the default runlevel, the available runlevels, and the actions to be taken when entering or leaving a runlevel.
The telinit command is used to change the current runlevel of the system or to send a signal to SysVinit. The telinit command takes a single argument, which can be either a runlevel number (0-6) or a special character. The syntax of the telinit command is:
telinit [runlevel|character]
The runlevel argument instructs SysVinit to switch to the specified runlevel. For example, to switch to runlevel 3, which is the multi-user mode with networking, use the following command:
telinit 3
The character argument instructs SysVinit to perform a special action. For example, to reboot the system, use the following command:
telinit 6
The q character argument instructs SysVinit to reload its configuration file, /etc/inittab, without changing the current runlevel. This is useful when the /etc/inittab file has been modified and the changes need to be applied. For example, to reload the /etc/inittab file, use the following command:
telinit q
The other options are not correct because:
A. reinit: This command does not exist in the Linux system. There is no such command as reinit in the Linux documentation or the man pages.
B. initreload: This command does not exist in the Linux system. There is no such command as initreload in the Linux documentation or the man pages.
C. telinit 7: This command is not valid because 7 is not a valid runlevel number. The valid runlevel numbers are 0-6, where 0 means halt, 1 means single-user mode, 2 means multi-user mode without networking, 3 means multi-user mode with networking, 4 means user-defined, 5 means graphical mode, and 6 means reboot. If you run this command, you will get an error message saying:
telinit: invalid runlevel: 7
E. init reinit: This command is not valid because reinit is not a valid argument for the init command. The init command is a synonym for the telinit command, and it takes the same arguments as the telinit command. The valid arguments for the init command are either a runlevel number (0-6) or a special character. If you run this command, you will get an error message saying:
init: invalid runlevel: reinit
What is the purpose of the Filesystem Hierarchy Standard?
It is a security model used to ensure files are organized according to their permissions and accessibility.
It provides unified tools to create, maintain and manage multiple filesystems in a common way.
It defines a common internal structure of inodes for all compliant filesystems.
Itis a distribution neutral description of locations of files and directories.
The Filesystem Hierarchy Standard is a distribution neutral description of locations of files and directories. According to the first result, it is a reference describing the conventions used for the layout of Unix-like systems. It is maintained by the Linux Foundation and the latest version is 3.0
Which of the following are modes of the vi editor? (Choose two.)
edit mode
insert mode
change mode
review mode
command mode
The modes of the vi editor that are correct are insert mode and command mode. The vi editor is a modal editor, which means that it has different modes for different operations. The insert mode allows the user to insert text into the file. The command mode allows the user to execute commands, such as saving, quitting, moving the cursor, searching, replacing, and so on. The user can switch between the modes by pressing certain keys, such as Esc, i, a, o, and others. The edit mode, change mode, and review mode are not valid modes of the vi editor. References: LPI Exam 101 Detailed Objectives, Topic 103: GNU and Unix Commands, Weight: 25, Objective 103.8: Use vi to create and edit files, vi editor
Which of the following is true for hard linked files? (Choose three.)
The output of stat will report hard instead of regular file.
The hard linked files have the same permissions and owner.
The hard linked files share the same inode.
The hard linked files are indicated by a -> when listed withls -1.
The hard linked files must be on the same filesystem.
A hard link is a directory entry that points to the same inode as another file. An inode is a data structure that stores the metadata and the location of the data blocks of a file. A hard link is not a separate file, but an additional name for an existing file. Therefore, the following statements are true for hard linked files:
The hard linked files have the same permissions and owner. Since the hard linked files point to the same inode, they share the same attributes, such as the file type, the file size, the access permissions, the owner, the group, and the timestamps. Any changes made to one hard link will affect the other hard links as well. For example, if you change the permissions of one hard link, the other hard links will have the same permissions. You can use the stat command to view the attributes of a file or a hard link.
The hard linked files share the same inode. This is the definition of a hard link. The inode number is a unique identifier for each file on a filesystem. The hard linked files have the same inode number, which means they point to the same data blocks on the disk. You can use the ls -i command to view the inode number of a file or a hard link.
The hard linked files must be on the same filesystem. A hard link cannot cross different filesystems or partitions, because each filesystem has its own inode table. A hard link can only point to an inode that exists on the same filesystem as the hard link. If you try to create a hard link to a file on a different filesystem, you will get an error message saying:
ln: failed to create hard link ‘link’ => ‘file’: Invalid cross-device link
The other statements are not true for hard linked files, because:
The output of stat will report hard instead of regular file. This is not true, because the stat command does not distinguish between a regular file and a hard link. The stat command will report the same file type for both the original file and the hard link, which is regular file. The only way to tell if a file is a hard link is to check the link count, which is the number of directory entries that point to the same inode. If the link count is more than one, it means there are hard links to the file. You can use the stat -c %h command to view the link count of a file or a hard link.
The hard linked files are indicated by a -> when listed with ls -l. This is not true, because the -> symbol is used to indicate a symbolic link, not a hard link. A symbolic link, also known as a soft link, is a special type of file that contains a path to another file or directory. A symbolic link does not point to the same inode as the target file, but to the name of the target file. A symbolic link has its own inode number, file type, permissions, and timestamps, which can be different from the target file. You can use the ls -l command to view the file type, permissions, and name of a file or a symbolic link. A symbolic link will have the file type l and the name will be followed by a -> symbol and the path to the target file. For example:
lrwxrwxrwx. 1 user user 9 Aug 29 15:10 link -> file
In the vi editor, what vi command will copy (but not paste) from the current line at the cursor and the following 16 lines (17 lines total)? Specify the correct vi command without spaces.
17yy
The vi editor is a text editor that operates in two modes: command mode and insert mode. In command mode, the user can enter commands to perform various operations on the text, such as copying, pasting, deleting, moving, searching, etc. In insert mode, the user can type text into the file. To switch from command mode to insert mode, the user can press i, a, o, or other keys. To switch from insert mode to command mode, the user can press Esc. The yy command is used to copy (yank) the current line into a buffer. The number before the yy command specifies how many lines to copy, starting from the current line. Therefore, the command 17yy will copy the current line and the following 16 lines (17 lines total) into a buffer. The buffer can then be pasted into another location by using the p or P command. Note that the command 17yy does not paste the copied lines, it only copies them. References:
LPI 101-500 Exam Objectives, Topic 103.8, Weight 4
LPI Learning Materials, Chapter 3.8, Advanced Scripting
Web Search Results, 1
Which of the following commands will produce the following output?
jobs
proclist
netstat
ps
The ps command will produce the output shown in the image. The ps command displays information about the processes running on the system. The output format can be customized by using different options. For example, ps -aux will show all processes with detailed information, such as user, PID, CPU, memory, command, and so on. The output in the image matches the format of ps -aux. The jobs command will show the status of jobs in the current shell. The proclist command is not a valid Linux command. The netstat command will show network connections, routing tables, and statistics. References: LPI Exam 101 Detailed Objectives, Topic 103: GNU and Unix Commands, Weight: 25, Objective 103.3: Perform basic file management, ps command, jobs command, netstat command
What does the command mount -a do?
It ensures that all file systems listed with the option noauto in /etc/fstab are mounted.
It shows all mounted file systems that have been automatically mounted.
It opens an editor with root privileges and loads /etc/fstab for editing.
It ensures that all file systems listed with the option auto in /etc/fstab are mounted.
It ensures that all file systems listed in /etc/fstab are mounted regardless of their options.
The command mount -a ensures that all file systems listed with the option auto in /etc/fstab are mounted. The /etc/fstab file contains the information about the file systems that can be mounted automatically or manually. The option auto means that the file system can be mounted automatically at boot time or when the command mount -a is issued. The option noauto means that the file system can only be mounted manually by specifying the device or mount point. The command mount -a ignores the file systems with the noauto option and mounts the rest of the file systems that are not already mounted. The other options are incorrect because they do not describe the correct behavior of the command mount -a. Option A is wrong because the command mount -a ignores the file systems with the noauto option. Option B is wrong because the command mount -a does not show any output, unless the -v option is used. To show the mounted file systems, the command mount without any arguments can be used. Option C is wrong because the command mount -a does not open any editor. To edit the /etc/fstab file, a text editor such as vi, nano, or gedit can be used. Option E is wrong because the command mount -a does not mount all file systems listed in /etc/fstab, but only those with the auto option. References:
[LPI Linux Essentials - 2.2 Mounting, Unmounting Filesystems]
Linux mount Command with Examples - phoenixNAP
How does the Linux command “mount -a” work? - Unix & Linux Stack Exchange
mount command in Linux with Examples - GeeksforGeeks
mountコマンドについてまとめました【Linuxコマンド集】
Pressing the Ctrl-C combination on the keyboard while a command is executing in the foreground sends which of the following signal codes?
1(SIGHUP)
2(SIGINT)
3(SIGQUIT)
9(SIGKILL)
15(SIGTERM)
The command line that will create or, in case it already exists, overwrite a file called data with the output of ls is ls > data. The > character is a redirection operator that redirects the standard output (STDOUT) of a command to a file. If the file does not exist, it will be created. If the file already exists, it will be overwritten. The 3> character is not a valid redirection operator. The >& character is a redirection operator that redirects both standard output (STDOUT) and standard error (STDERR) of a command to a file. The >> character is a redirection operator that appends the standard output (STDOUT) of a command to a file, without overwriting the existing file contents. References: LPI Exam 101 Detailed Objectives, Topic 103: GNU and Unix Commands, Weight: 25, Objective 103.3: Perform basic file management, Redirection
Which of the following commands will print important system information such as the kernel version and machine hardware architecture?
sysinfo
uname
lspci
arch
info
The commands that will print important system information such as the kernel version and machine hardware architecture are uname and arch. The uname command prints system information, such as the kernel name, release, version, machine, processor, hardware platform, and operating system. The arch command prints the machine hardware name, which is equivalent to uname -m. For example, uname -a will print Linux 5.10.0-8-amd64 #1 SMP Debian 5.10.46-4 (2021-08-03) x86_64 GNU/Linux, and arch will print x86_64. The sysinfo command is not a valid Linux command. The lspci command prints information about PCI buses and devices in the system. The info command prints documentation for a given topic or command. References: LPI Exam 101 Detailed Objectives, Topic 103: GNU and Unix Commands, Weight: 25, Objective 103.1: Work on the command line, uname command, arch command, lspci command, info command
How can the list of files that would be installed by the RPM package file apache-xml.rpm be previewed?
rpm –qp apache-xml.rpm
rpm –qv apache-xml.rpm
rpm –ql apache-xml.rpm
rpm –qpl apache-xml.rpm
The command rpm -qpl apache-ql.rpm is used to preview the list of files that would be installed by the RPM package file apache-xml.rpm. This command queries the package file without installing it and lists the contents of the package. Here’s what each part of the command means:
rpm is the command-line tool used for managing RPM packages on Linux systems.
-qpl are options for the rpm command.
q stands for query mode
l stands for list the contents of the package.
p specifies that the package being queried is not installed, but is a file located on the system.
apache-xml.rpm is the name of the RPM package file you want to query.
So, when you run this command, it will display a list of all the files that are included in the apache-xml.rpm package file, without installing it. This can be useful for checking what files are included in the package before installing it or comparing it with another version of the package.
The other commands are either invalid or do not perform the same function as the correct answer. For example:
rpm -qp apache-xml.rpm will only display the name and version of the package, not the list of files.
rpm -qv apache-xml.rpm will display the verbose information about the package, such as the description, license, and changelog, but not the list of files.
rpm -ql apache-xml.rpm will list the files that are installed on the system by the apache-xml.rpm package, but only if the package is already installed. If the package is not installed, it will return an error.
In order to display all currently mounted filesystems, which of the following commands could be used? (Choose TWO correct answers.)
cat /proc/self/mounts
free
mount
lsmounts
cat /proc/filesystems
The correct commands to display all currently mounted filesystems are cat /proc/self/mounts and mount. The cat /proc/self/mounts command reads the contents of the /proc/self/mounts file, which is a symbolic link to /proc/mounts. This file contains information about all the filesystems that are currently mounted on the system, as reported by the kernel. The mount command without any arguments shows all the mounted filesystems, as recorded by the mount and umount commands. The other options are incorrect because they do not display the mounted filesystems. The free command shows the amount of free and used memory in the system. The lsmounts command is not a standard Linux command. The cat /proc/filesystems command shows the filesystem types that are supported by the kernel. References:
[LPI Linux Essentials - 2.2 Mounting, Unmounting Filesystems]
How to get the complete and exact list of mounted filesystems in Linux? - Unix & Linux Stack Exchange
4 Commands to List Mounted File Systems in Linux - Linux Shell Tips
How To Show Mounted Devices In Linux Operating System
How to Check if a Filesystem is Mounted in Linux?
Which of the following commands set the sticky bit for the directory /tmp? (Choose TWO correct answers.)
chmod +s /tmp
chmod +t /tmp
chmod 1775 /tmp
chmod 4775 /tmp
chmod 2775 /tmp
The sticky bit is a special permission bit that can be set for directories. It prevents users from deleting or renaming files in the directory that they do not own, even if they have write permission on the directory. This is useful for shared directories like /tmp, where users can create temporary files but not interfere with other users’ files12. The command chmod +t /tmp sets the sticky bit for the directory /tmp by adding the letter t to the end of the permission string. The command chmod 1775 /tmp also sets the sticky bit for the directory /tmp by adding the number 1 to the beginning of the octal mode. The number 1 represents the sticky bit in the octal notation34. The commands chmod +s /tmp, chmod 4775 /tmp, and chmod 2775 /tmp do not set the sticky bit, but rather the setuid or setgid bits, which are different special permission bits that affect how programs are executed5. References: 1: Sticky bit - Wikipedia 2: Linux Sticky Bit Concept Explained with Examples 3: chmod(1) - Linux man page 4: Understanding Linux File Permissions 5: Setuid and Setgid on Linux - GeeksforGeeks
Which of the following commands will mount an already inserted CD-ROM in /dev/sr0 onto an existing directory /mnt/cdrom when issued with root privileges?
mount /dev/cdrom /mnt/cdrom
mount /dev/sr0 /mnt/cdrom
mount –t cdrom /dev/sr0 /mnt/cdrom
mount –l cdrom /dev/sr0 /mnt/cdrom
mount –f /dev/sr0/mnt/cdrom
The mount command is used to attach a filesystem to a directory on the system, which is called a mount point. The mount command requires the device name or the UUID of the filesystem as the first argument, and the mount point as the second argument. Optionally, the mount command can also take some options, such as the filesystem type, the mount options, and the label. The syntax of the mount command is:
mount [options] device mountpoint
In this question, the device name of the CD-ROM is /dev/sr0, and the mount point is /mnt/cdrom. Therefore, the correct command to mount the CD-ROM is:
mount /dev/sr0 /mnt/cdrom
This command will mount the CD-ROM as a read-only filesystem with the type iso9660, which is the standard format for optical discs. The mount command can automatically detect the filesystem type and the mount options, so there is no need to specify them explicitly. However, if you want to specify them, you can use the -t and -o options, respectively. For example, the following command is equivalent to the previous one:
mount -t iso9660 -o ro /dev/sr0 /mnt/cdrom
The other options are not correct because:
A. mount /dev/cdrom /mnt/cdrom: This command may work on some systems, but it is not guaranteed to be correct. The /dev/cdrom is usually a symbolic link to the actual device name of the CD-ROM, which can vary depending on the system. For example, on some systems, the /dev/cdrom may point to /dev/sr0, but on others, it may point to /dev/scd0 or /dev/hdc. Therefore, it is better to use the actual device name of the CD-ROM, which can be found by using the lsblk or the dmesg command.
C. mount -t cdrom /dev/sr0 /mnt/cdrom: This command is not valid because cdrom is not a valid filesystem type. The filesystem type for optical discs is iso9660, not cdrom. The mount command will fail with an error message saying:
mount: unknown filesystem type ‘cdrom’
D. mount -l cdrom /dev/sr0 /mnt/cdrom: This command is not valid because -l is not a valid option for the mount command. The -l option is used to list all the mounted filesystems, not to mount a filesystem. The mount command will fail with an error message saying:
mount: can’t find /dev/sr0 in /etc/fstab
E. mount -f /dev/sr0/mnt/cdrom: This command is not valid because it is missing a space between the device name and the mount point. The mount command requires two separate arguments for the device name and the mount point, separated by a space. Also, the -f option is used to fake the mount operation, not to perform the actual mount. The mount command will fail with an error message saying:
mount: /dev/sr0/mnt/cdrom: mount point does not exist.
Which of the following commands prints a list of available package updates when using RPM-based package management?
dpkg list
yum list
dpkg check-update
yum check-update
yum list-update
The command yum check-update prints a list of available package updates when using RPM-based package management. This command queries all enabled repositories and shows the packages that have updates available, along with the new version number. This command does not actually update any packages, but only lists them. To update the packages, the command yum update can be used. The other commands are either invalid or belong to a different package management system. dpkg is a low-level tool for Debian-based package management, and yum list shows all available packages in the repositories, not just the ones that have updates. References:
Linux Package Management with Yum, RPM, Apt, Dpkg, Aptitude and Zypper - Part 9
rpm - RPM package management tool | Linux Docs
RPM Command in Linux | Linuxize
Which of the following commands makes /bin/foo executable by everyone but writable only by its owner?
chmod u=rwx,go=rx /bin/foo
chmod o+rwx,a+rx /bin/foo
chmod 577 /bin/foo
chmod 775 /bin/foo
The correct command to make /bin/foo executable by everyone but writable only by its owner is chmod u=rwx,go=rx /bin/foo. This command uses the symbolic method to set the permissions for the user (u), group (g), and others (o) classes. The equal sign (=) means that the permissions are set exactly as specified, not added or removed. The letters r, w, and x represent the read, write, and execute permissions respectively. The comma (,) separates the different classes. The command means that the user has read, write, and execute permissions (rwx), while the group and others have only read and execute permissions (rx). The other options are incorrect because they use the wrong syntax or values for the chmod command. Option B uses the wrong indicators for the classes. The letter o means others, not owner. The letter a means all, not group. Option C uses the numeric method, but the value 577 is not correct. The numeric method uses octal numbers (0-7) to represent the permissions for each class. The first digit is for the user, the second for the group, and the third for others. Each digit is the sum of the values for the read (4), write (2), and execute (1) permissions. For example, 7 means rwx, 6 means rw-, 5 means r-x, and so on. The value 577 means that the user has read, write, and execute permissions (rwx), the group has read and execute permissions (r-x), but the others have only write and execute permissions (w-x), which is not what the question asked. Option D uses the numeric method, but the value 775 is not correct. The value 775 means that the user and the group have read, write, and execute permissions (rwx), while the others have only read and execute permissions (r-x). This means that the group can also write to the file, which is not what the question asked. References:
[LPI Linux Essentials - 1.3 Basic File Management]
[LPI Linux Essentials - 2.1 Using Devices, Linux Filesystems, Filesystem Hierarchy Standard]
[LPI Linux Essentials - 2.2 Mounting, Unmounting Filesystems]
[LPI Linux Essentials - 2.3 Disk Partitions]
How to Use the chmod Command on Linux - How-To Geek
Chmod Command in Linux (File Permissions) | Linuxize
Chmod command in Linux with examples - GeeksforGeeks
Which of the following is the device file name for the second partition on the only SCSI drive?
/dev/hda1
/dev/sda2
/dev/sd0a2
/dev/sd1p2
The correct device file name for the second partition on the only SCSI drive is /dev/sda2. This is because SCSI drives use the naming scheme sdX, where X is a letter starting from a for the first drive, b for the second drive, and so on. The partitions on each drive are numbered from 1 to the maximum number of partitions supported by the drive. Therefore, the first partition on the first SCSI drive is /dev/sda1, the second partition on the first SCSI drive is /dev/sda2, the first partition on the second SCSI drive is /dev/sdb1, and so on. The other options are incorrect because they do not follow the SCSI naming scheme. Option A is wrong because it uses the naming scheme for IDE drives, which is hdX. Option C is wrong because it uses the naming scheme for BSD drives, which is sdXaY, where X is a number and Y is a letter. Option D is wrong because it uses the naming scheme for Solaris drives, which is sdXpY, where X is a number and Y is a number. References:
[LPI Linux Essentials - 2.1 Using Devices, Linux Filesystems, Filesystem Hierarchy Standard]
[LPI Linux Essentials - 2.2 Mounting, Unmounting Filesystems]
[LPI Linux Essentials - 2.3 Disk Partitions]
Device file - ArchWiki
What is the Linux drive naming scheme? - Ask Ubuntu
Which of the following are filesystems which can be used on Linux root partitions? (Choose two.)
NTFS
ext3
XFS
VFAT
swap
The Linux root partition is the partition that contains the root filesystem, which is the top-level directory of the filesystem hierarchy. The root filesystem contains the essential files and directories that are needed to boot the system, such as the kernel, the init system, the configuration files, the libraries, the binaries, and the device files. The root partition can be formatted with different filesystems, depending on the support of the kernel and the boot loader. Some of the common filesystems that can be used on Linux root partitions are:
ext3: This is the third extended filesystem, which is a journaling filesystem that provides metadata and data integrity, fast recovery, and backward compatibility with ext2. ext3 is widely supported by most Linux distributions and boot loaders, and it is considered stable and reliable. ext3 has been the default filesystem for many Linux distributions, such as Debian, Ubuntu, Fedora, and CentOS, until it was replaced by ext4.
XFS: This is a high-performance 64-bit journaling filesystem that supports large files and volumes, parallel I/O, extent-based allocation, and online defragmentation. XFS is designed for scalability and efficiency, and it is suitable for applications that handle large amounts of data, such as databases, video editing, and data warehousing. XFS is the default filesystem for Red Hat Enterprise Linux and SUSE Linux Enterprise Server, and it is also supported by other Linux distributions and boot loaders.
The other options are not valid filesystems for Linux root partitions, because:
NTFS: This is the New Technology File System, which is the default filesystem for Windows operating systems. NTFS supports features such as journaling, encryption, compression, and access control. NTFS is not natively supported by the Linux kernel, and it requires a third-party driver, such as ntfs-3g, to read and write to NTFS partitions. NTFS is not compatible with the Linux boot loader, and it cannot be used as the root filesystem for Linux.
VFAT: This is the Virtual File Allocation Table, which is an extension of the FAT32 filesystem that supports long file names. VFAT is a legacy filesystem that is mainly used for compatibility with older Windows and DOS systems. VFAT does not support features such as journaling, permissions, and symbolic links, and it has limitations on the file and volume size. VFAT is not suitable for the root filesystem for Linux, and it is not supported by the Linux boot loader.
swap: This is not a filesystem, but a special type of partition that is used to store the memory pages that are not currently in use by the system. swap is used to extend the physical memory of the system, and it can improve the performance and stability of the system. swap is not a mountable partition, and it cannot be used as the root filesystem for Linux.
Which of the following options is used in a GRUB Legacy configuration file to define the amount of time that the GRUB menu will be shown to the user?
hidemenu
splash
timeout
showmenu
The timeout option in a GRUB Legacy configuration file is used to define the amount of time (in seconds) that the GRUB menu will be shown to the user before booting the default entry. The timeout option is usually located in the /boot/grub/menu.lst file. For example, timeout 10 will display the GRUB menu for 10 seconds. To disable the timeout and wait for user input indefinitely, the value of timeout can be set to -1. To boot immediately without displaying the menu, the value of timeout can be set to 0. The other options are not valid for the GRUB Legacy configuration file. References:
GRUB Legacy - ArchWiki
How do I set the grub timeout and the grub default boot entry?
How to Remove the Timeout From GRUB Menu
Typically, which top level system directory is used for files and data that change regularly while the system is running and are to be kept between reboots? (Specify only the top level directory)
/var
/var/,
Var
var/
The top-level system directory that is used for files and data that change regularly while the system is running and are to be kept between reboots is /var. The /var directory contains variable data that changes in size as the system runs. For instance, log files, mail directories, databases, and printing spools are stored in /var. These files and data are not temporary and need to be preserved across system reboots. The /var directory is one of the few directories that are recommended to be on a separate partition, according to the Filesystem Hierarchy Standard (FHS)1. This is because the /var directory can grow unpredictably and fill up the / partition, which can cause system instability or failure. By having /var on a separate partition, we can limit the amount of disk space that can be used by variable data and prevent users from affecting the / partition. The /var directory is also a common target for malicious attacks, so having it on a separate partition can improve the security and isolation of the system. References:
Filesystem Hierarchy Standard
An administrator has issued the following command:
grub-install --root-directory=/custom-grub /dev/sda
In which directory will new configuration files be found? (Provide the full directory path only without the filename)
/custom-grub/boot/grub/
/custom-grub/boot/grub
The command grub-install is used to install GRUB on a device or a partition. The option --root-directory specifies the directory where GRUB images are put. The default is /boot/grub. The argument /dev/sda specifies the device where GRUB is installed, usually the Master Boot Record (MBR) of the disk. Therefore, the command grub-install --root-directory=/custom-grub /dev/sda will install GRUB on the MBR of /dev/sda and put the GRUB images under the directory /custom-grub/boot/grub. This means that the new configuration files, such as grub.cfg, will be found in the directory /custom-grub/boot/grub. References:
GNU GRUB Manual 2.06: Installing GRUB using grub-install
Installing GRUB using grub-install - GNU GRUB Manual 0.97
In which directory must definition files be placed to add additional repositories to yum?
/etc/yum.repos.d
/etc/yum.repos.d/
yum.repos.d
yum.repos.d/
B
The /etc/yum.repos.d/ directory contains configuration files for additional yum repositories. Each file in this directory should end with .repo and contain information about one or more repositories. The yum command will read all the files in this directory and use them as sources for software packages. The format of the .repo files is similar to the /etc/yum.conf file, which contains the main configuration options for yum. Each .repo file can have one or more sections, each starting with [repository] where repository is a unique identifier for the repository. The section can have various options, such as name, baseurl, enabled, gpgcheck, etc. For example, a .repo file for the EPEL repository could look like this:
[epel] name=Extra Packages for Enterprise Linux 7 - $basearch enabled=1 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7
Which function key is used to start Safe Mode in Windows NT?
F10
F8
F6
Windows NT does not support Safe Mode
The function key that is used to start Safe Mode in Windows NT is none of the above, because Windows NT does not support Safe Mode. Safe Mode is a diagnostic mode of Windows that starts the system with minimal drivers and services, allowing the user to troubleshoot problems and restore the system to a normal state1. Safe Mode was introduced in Windows 95 and later versions, but not in Windows NT 4.0 and earlier2.
The other options are incorrect for the following reasons:
F10. This function key is used to access the Recovery Console in Windows XP, which is a command-line interface that allows the user to perform various administrative tasks, such as repairing the boot sector, restoring the registry, or copying files3. The Recovery Console is not the same as Safe Mode, and it is not available in Windows NT.
F8. This function key is used to access the Advanced Boot Options menu in Windows Vista and later versions, which allows the user to choose from various boot modes, including Safe Mode, Last Known Good Configuration, Debugging Mode, and others4. In Windows NT, pressing F8 during startup only displays a simple menu with three options: Normal, VGA mode, and Boot Logging5. None of these options are equivalent to Safe Mode.
F6. This function key is used to load additional drivers during the installation of Windows, such as SCSI or RAID drivers, from a floppy disk or a USB flash drive6. This function key has nothing to do with Safe Mode, and it is not relevant after the installation is completed.
What can the Logical Volume Manager (LVM) be used for? (Choose THREE correct answers.)
To create RAID 9 arrays.
To dynamically change the size of logical volumes.
To encrypt logical volumes.
To create snapshots.
To dynamically create or delete logical volumes.
The Logical Volume Manager (LVM) is a tool that allows the creation and management of logical volumes on Linux systems. Logical volumes are partitions that can span multiple physical disks and can be resized or deleted without affecting the rest of the system. Some of the benefits of using LVM are:
To dynamically change the size of logical volumes. LVM allows the user to increase or decrease the size of a logical volume without having to repartition the disk or reboot the system. This can be useful for allocating more space to a volume that is running out of space, or freeing up space from a volume that is not needed anymore.
To create snapshots. LVM allows the user to create a snapshot of a logical volume, which is a copy of the volume at a certain point in time. Snapshots can be used for backup purposes, as they can be restored to the original volume if needed. Snapshots can also be used for testing purposes, as they can be mounted as read-only or read-write volumes without affecting the original volume.
To dynamically create or delete logical volumes. LVM allows the user to create or delete logical volumes on the fly, without having to repartition the disk or reboot the system. This can be useful for creating temporary volumes for specific purposes, or deleting volumes that are no longer needed.
LVM cannot be used for the following purposes:
To create RAID 9 arrays. RAID 9 is not a valid RAID level, and LVM does not support RAID functionality. RAID is a technique that uses multiple disks to provide redundancy, performance, or both. RAID can be implemented at the hardware level, by using a RAID controller, or at the software level, by using tools such as mdadm or dmraid. LVM can work on top of RAID devices, but it cannot create them.
To encrypt logical volumes. LVM does not provide encryption functionality. Encryption is a technique that protects data from unauthorized access by using a secret key to transform the data into an unreadable form. Encryption can be implemented at the disk level, by using tools such as dm-crypt or LUKS, or at the file system level, by using tools such as eCryptfs or EncFS. LVM can work on top of encrypted devices, but it cannot encrypt them.
Which of the following commands lists all currently installed packages when using RPM package management?
yum --query --all
yum --list --installed
rpm --query --all
rpm --list –installed
The command that lists all currently installed packages when using RPM package management is rpm --query --all. This command displays information about all the packages that are currently installed on the system, including their name, version, release, and architecture1. The output can be customized by using various query options and format specifiers2.
The other commands are either invalid or related to YUM, not RPM. yum --query --all is not a valid YUM command, as YUM does not have a --query option3. yum --list --installed is a valid YUM command, but it lists the packages from the YUM repositories, not the RPM database3. rpm --list --installed is not a valid RPM command, as RPM does not have a --list option2.
You want to preview where the package file, apache-xml.i386.rpm, will install its files before installing it. What command do you issue?
rpm -qp apache-xml.i386.rpm
rpm -qv apache-xml.i386.rpm
rpm -ql apache-xml.i386.rpm
rpm -qpl apache-xml.i386.rpm
Which of the following is correct when talking about mount points?
Every existing directory can be used as a mount point.
Only empty directories can be used as a mount point.
Directories need to have the SetUID flag set to be used as a mount point.
Files within a directory are deleted when the directory is used as a mount point.
The correct answer when talking about mount points is that every existing directory can be used as a mount point. A mount point is a directory in the Linux file-system where a file system, partition, or storage device can be attached and accessed1. To create a mount point, you need root privileges. Mounting means making the contents of the attached file system, partition, or storage device available in the mount point directory1.
The other options are incorrect for the following reasons:
Only empty directories can be used as a mount point. This is not true, as any directory can be used as a mount point, regardless of whether it contains files or not. However, if the directory is not empty, the files inside it will be hidden by the mounted file system until it is unmounted2. Therefore, it is recommended to use empty directories as mount points to avoid confusion and data loss2.
Directories need to have the SetUID flag set to be used as a mount point. This is not true, as the SetUID flag is a special permission that allows a file to be executed with the privileges of its owner, regardless of who runs it3. This flag has nothing to do with mounting file systems, and it is not required for a directory to be used as a mount point4.
Files within a directory are deleted when the directory is used as a mount point. This is not true, as the files within a directory are not deleted when the directory is used as a mount point. They are only hidden by the mounted file system until it is unmounted2. The files are still present on the disk and can be recovered by unmounting the file system or using another mount point to access them2.
The dpkg-____ command will ask configuration questions for a specified package, just as if the package were being installed for the first time.
dpkg-reconfigure
The dpkg-reconfigure command is used to reconfigure an already installed package. It asks configuration questions for the package, just as if the package were being installed for the first time. This can be useful if the user wants to change some settings or options for the package without reinstalling it. The dpkg-reconfigure command can also be used to fix a broken package configuration or to restore the default settings. References:
dpkg-reconfigure(8) - Linux man page
Linux Professional Institute: Exam 101 Objectives
When removing a package, which of the following dpkg options will completely remove the files including configuration files?
--clean
--delete
--purge
–remove
When removing a package on a system using dpkg package management, the --purge option ensures that configuration files are removed as well. The --purge option is equivalent to the --remove option followed by the --purge-config-files option, which removes any configuration files that are marked as obsolete. The --remove option only removes the package files, but leaves the configuration files intact. The --clean option removes any .deb files from the local cache, but does not affect the installed packages. The --delete option is not a valid option for dpkg. References:
1, 102.4 Lesson 1
3, 101-500 Exam - Free Questions and Answers - ITExams.com
man dpkg
After modifying GNU GRUB's configuration file, which command must be run for the changes to take effect?
kill -HUP $(pidof grub)
grub-install
grub
No action is required
After modifying GNU GRUB’s configuration file, which is usually located at /etc/default/grub, the command that must be run for the changes to take effect is grub-install12. The grub-install command is used to install GRUB on a device or partition, and to update the boot sector and the core image of GRUB3. The command takes the following basic syntax:
$ grub-install [options] install_device
The install_device argument specifies the device or partition where GRUB should be installed, such as /dev/sda or /dev/sda1. The options can be used to control various aspects of the installation, such as the target platform, the boot directory, the force mode, the verbosity level, etc3.
The grub-install command also invokes the grub-mkconfig command, which generates the GRUB configuration file (usually located at /boot/grub/grub.cfg) based on the settings in /etc/default/grub and the scripts in /etc/grub.d4. The grub-mkconfig command can also be run separately to update the GRUB configuration file without reinstalling GRUB on the device or partition4.
The other options in the question are not correct because:
A. kill -HUP $(pidof grub): This command would send the hangup signal (HUP) to the process ID (PID) of grub, which is a command-line interface for GRUB. This would not update the GRUB configuration file or install GRUB on the device or partition.
C. grub: This command would run the command-line interface for GRUB, which allows the user to interact with GRUB and execute various commands. This would not update the GRUB configuration file or install GRUB on the device or partition, unless the user explicitly runs the appropriate commands within the interface.
D. No action is required: This option is false, because modifying the /etc/default/grub file alone does not affect the GRUB configuration file or the GRUB installation. The user needs to run either grub-install or grub-mkconfig to apply the changes.
When using rpm --verify to check files created during the installation of RPM packages, which of the following information is taken into consideration? (Choose THREE correct answers.)
Timestamps
MD5 checksums
Inodes
File sizes
GnuPG signatures
When using rpm --verify to check files created during the installation of RPM packages, the following information is taken into consideration:
Timestamps. RPM compares the modification time of the installed files with the original time stored in the RPM database. If the file has been modified after installation, the timestamp will differ and RPM will report it with an M flag1.
MD5 checksums. RPM calculates the MD5 checksum of the installed files and compares it with the original checksum stored in the RPM database. If the file has been altered in any way, the checksum will differ and RPM will report it with an 5 flag1.
File sizes. RPM compares the size of the installed files with the original size stored in the RPM database. If the file has been truncated or appended, the size will differ and RPM will report it with an S flag1.
RPM does not take into consideration the following information:
Inodes. RPM does not check the inode number of the installed files, as it is not a reliable indicator of file identity. The inode number can change if the file is moved, copied, or restored from a backup2.
GnuPG signatures. RPM does not verify the GnuPG signatures of the installed files, as they are not part of the RPM package format. The GnuPG signatures are used to verify the authenticity and integrity of the RPM package files before installation, not after3.
Which of the following commands lists the dependencies of a given dpkg package?
apt-cache depends-onpackage
apt-cache dependencies package
apt-cache depends package
apt-cache requires package
The apt-cache command is used to query the APT cache for information about packages. The depends option shows a listing of each dependency a package has and all the possible other packages that can fulfill that dependency. For example, apt-cache depends ubuntu-restricted-extras will show the dependencies of the ubuntu-restricted-extras package. The other options are not valid for the apt-cache command. References:
How to Check Dependencies of a Package in Ubuntu/Debian-based Linux Distributions
Check DEB package dependencies on Ubuntu / Debian
Which file should be edited to select the network locations from which Debian installation package files are loaded?
/etc/dpkg/dpkg.cfg
/etc/apt/apt.conf
/etc/apt/apt.conf.d
/etc/apt/sources.list
/etc/dpkg/dselect.cfg
The /etc/apt/sources.list file is the main configuration file for the Advanced Package Tool (apt), which is used to manage Debian installation package files. This file contains a list of repositories, or sources, from which apt can download and install packages. Each repository is specified by a line that has the following format:
type uri suite [component1] [component2] […]
Where:
type is the access method, such as http, ftp, file, etc.
uri is the Uniform Resource Identifier (URI) of the repository, such as
suite is the distribution code name or archive name, such as stable, testing, unstable, etc.
component is an optional section of the repository, such as main, contrib, non-free, etc.
For example, a typical sources.list file for Debian stable could look like this:
deb stable main contrib non-free deb-src stable main contrib non-free
deb stable/updates main contrib non-free deb-src stable/updates main contrib non-free
deb stable-updates main contrib non-free deb-src stable-updates main contrib non-free
The first two lines specify the main repository for Debian stable, with both binary (deb) and source (deb-src) packages. The next two lines specify the security updates repository for Debian stable, which contains important security fixes. The last two lines specify the stable-updates repository, which contains packages that have been updated after the release of Debian stable.
By editing the /etc/apt/sources.list file, one can select the network locations from which Debian installation package files are loaded. However, it is recommended to use a graphical or command-line tool, such as aptitude or synaptic, to manage the sources.list file, as they can handle the syntax and avoid errors.
Copyright © 2021-2026 CertsTopics. All Rights Reserved
