You have an Azure Synapse Analytics dedicated SQL pool named SQL1 that contains a hash-distributed fact table named Table1.
You need to recreate Table1 and add a new distribution column. The solution must maximize the availability of data.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

You have an Azure Synapse Analytics workspace that contains three pipelines and three triggers named Trigger 1. Trigger2, and Tiigger3.
Trigger 3 has the following definition.


You have an Azure data factory.
You need to examine the pipeline failures from the last 60 days.
What should you use?
You are building an Azure Stream Analytics job that queries reference data from a product catalog file. The file is updated daily.
The reference data input details for the file are shown in the Input exhibit. (Click the Input tab.)
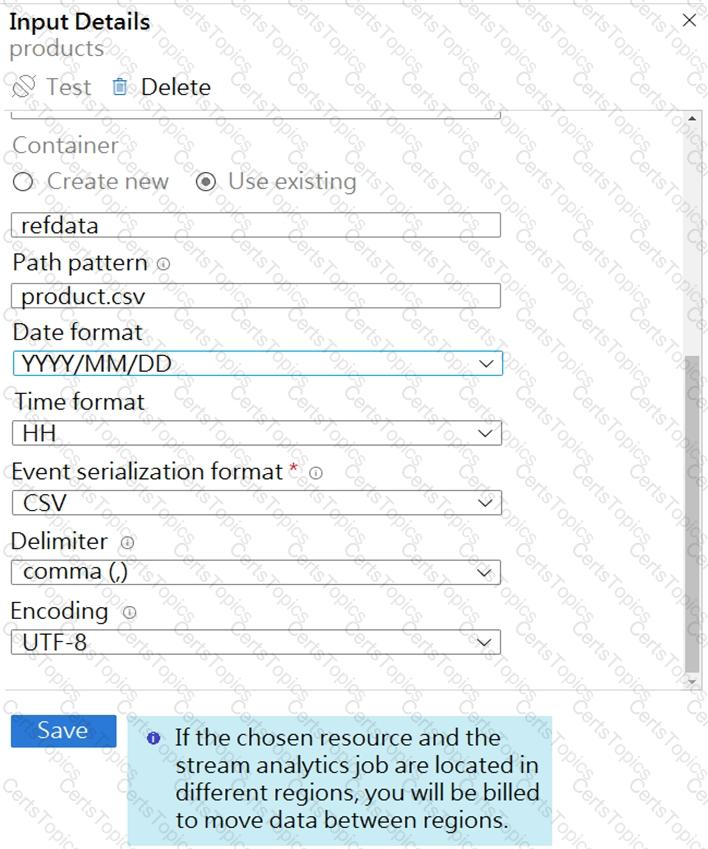
The storage account container view is shown in the Refdata exhibit. (Click the Refdata tab.)
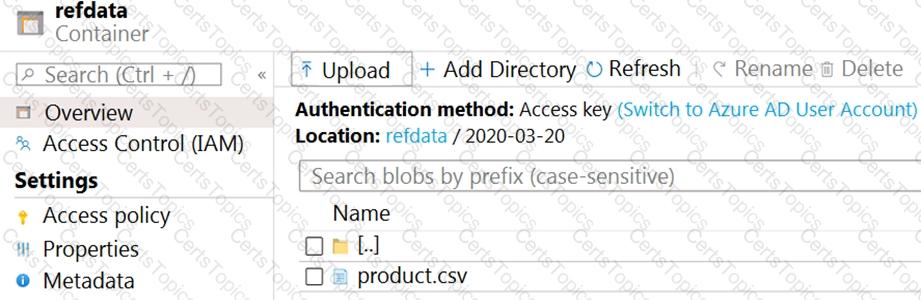
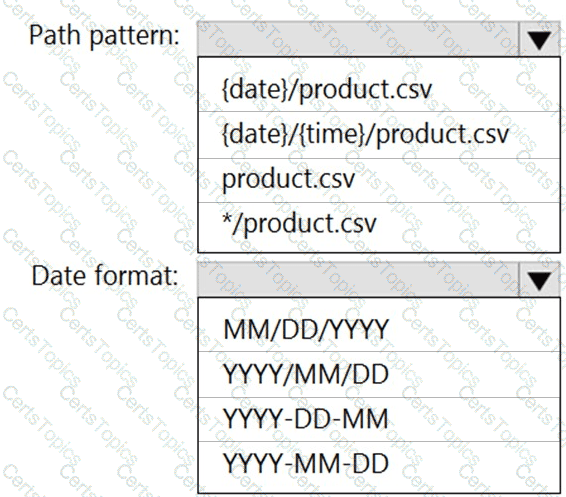
You need to configure the Stream Analytics job to pick up the new reference data.
What should you configure? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Copyright © 2021-2026 CertsTopics. All Rights Reserved




