A VPLEX Metro cluster is being installed for a company that is planning to create distributed volumes with 200 TB of storage. Based on this requirement, and consistent with
EMC best practices, what should be the minimum size for logging volumes at each cluster?
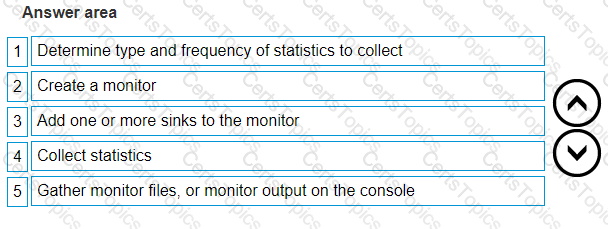
Which command is used to display available statistics for monitoring VPLEX?
A RAID-C device has been built from a 100 GB extent and a 30 GB extent. How can this device be expanded?
What are the two common use cases of the VPLEX Mobility feature?
In preparing a host to access its storage from VPLEX, what is considered a best practice when zoning?
What is an EMC best practice for connecting VPLEX to back-end arrays?
What is the maximum number of synchronous consistency groups supported by VPLEX?

Refer to the exhibit.
Which Director-A port can be zoned to a host initiator?
What is a consideration when using VPLEX RecoverPoint enabled consistency groups?
When using the VIAS method of storage provisioning after selecting a cluster, what determines the set of arrays available from which to provision storage?
A storage administrator created a local RAID-0 virtual volume. However, the administrator decided to increase data protection by requiring a distributed virtual volume.
What is the recommended method to change the local volume to a distributed volume?
A customer engineer has installed VS2 VPLEX hardware, assigned IPs, and made the VPLEX ready to be configured. Which interface and port should be used to ssh to when
using the EZ Setup wizard?
What information is required to configure ESRS for VPLEX?
Which type of statistics is used to track latencies, determine median, mode, percentiles, minimums, and maximums?
What are the requirements to upgrade a VPLEX from VS2 to VS6?
Which performance statistics are collected as histograms and used to track latencies to display minimums and maximums?
How many copies can RecoverPoint maintain in a MetroPoint topology?
Copyright © 2021-2026 CertsTopics. All Rights Reserved