Refer to the exhibit.

You are building a decision tree. In this exhibit, four variables are listed with their respective values of info-gain.
Based on this information, on which attribute would you expect the next split to be in the decision tree?
Select the correct problems which can be solved using SVMs
Regularization is a very important technique in machine learning to prevent overfitting. Mathematically speaking, it adds a regularization term in order to prevent the coefficients to fit so perfectly to overfit. The difference between the L1 and L2 is...
You have modeled the datasets with 5 independent variables called A,B,C,D and E having relationships which is not dependent each other, and also the variable A,B and C are continuous and variable D and E are discrete (mixed mode).
Now you have to compute the expected value of the variable let say A, then which of the following computation you will prefer
A researcher is interested in how variables, such as GRE (Graduate Record Exam scores), GPA (grade point average) and prestige of the undergraduate institution, effect admission into graduate school. The response variable, admit/don't admit, is a binary variable.
Above is an example of
Select the correct option from the below
Suppose that we are interested in the factors that influence whether a political candidate wins an election. The outcome (response) variable is binary (0/1); win or lose. The predictor variables of interest are the amount of money spent on the campaign, the amount of time spent campaigning negatively and whether or not the candidate is an incumbent.
Above is an example of
You are working on a problem where you have to predict whether the claim is done valid or not. And you find that most of the claims which are having spelling errors as well as corrections in the manually filled claim forms compare to the honest claims. Which of the following technique is suitable to find out whether the claim is valid or not?
A website is opened 3 times by a user. What is the probability of he clicks 2 times the advertisement, is best calculated by
Scenario: Suppose that Bob can decide to go to work by one of three modes of transportation,
car, bus, or commuter train. Because of high traffic, if he decides to go by car. there is a 50% chance he will be late. If he goes by bus, which has special reserved lanes but is sometimes overcrowded, the probability of being late is only 20%. The commuter train is almost never late, with a probability of only 1 %, but is more expensive than the bus.
Suppose that Bob is late one day, and his boss wishes to estimate the probability that he drove to work that day by car. Since he does not know Which mode of transportation Bob usually uses, he gives a prior probability of 1 3 to each of the three possibilities. Which of the following method the boss will use to estimate of the probability that Bob drove to work?
What is the probability that the total of two dice will be greater than 8, given that the first die is a 6?
A denote the event 'student is female' and let B denote the event 'student is French'. In a class of 100 students suppose 60 are French, and suppose that 10 of the French students are females. Find the probability that if I pick a French student, it will be a girl, that is, find P(A|B).
Support vector machines (SVMs) are a set of supervised learning methods used for
A bio-scientist is working on the analysis of the cancer cells. To identify whether the cell is cancerous or not, there has been hundreds of tests are done with small variations to say yes to the problem. Given the test result for a sample of healthy and cancerous cells, which of the following technique you will use to determine whether a cell is healthy?
Suppose you have been given two Random Variables X and Y, whose joint distribution is already known, the marginal distribution of X is simply the probability distribution of X averaging over information about Y. It is the probability distribution of X when the value of Y is not known. So how do you calculate the marginal distribution of X
Select the correct option which applies to L2 regularization
In which lifecycle stage are appropriate analytical techniques determined?
Logistic regression is a model used for prediction of the probability of occurrence of an event. It makes use of several variables that may be......
If E1 and E2 are two events, how do you represent the conditional probability given that E2 occurs given that E1 has occurred?
Which of the following metrics are useful in measuring the accuracy and quality of a recommender system?
Copyright © 2021-2026 CertsTopics. All Rights Reserved

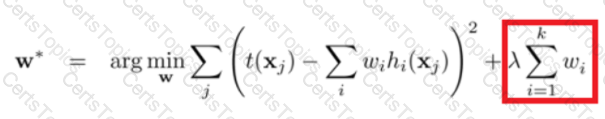 A picture containing text
Description automatically generated
A picture containing text
Description automatically generated Text
Description automatically generated
Text
Description automatically generated Text
Description automatically generated
Text
Description automatically generated Text
Description automatically generated
Text
Description automatically generated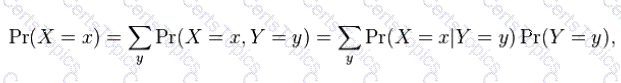 Text
Description automatically generated with low confidence
Text
Description automatically generated with low confidence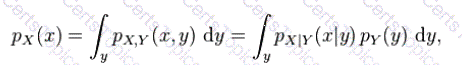 Diagram
Description automatically generated with medium confidence
Diagram
Description automatically generated with medium confidence Text, letter
Description automatically generated
Text, letter
Description automatically generated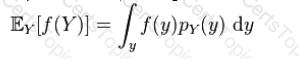 A picture containing diagram
Description automatically generated
A picture containing diagram
Description automatically generated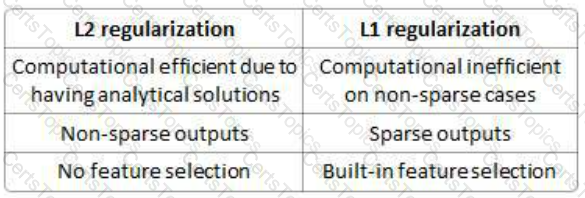 Table
Description automatically generated
Table
Description automatically generated