Query History provides Databricks SQL users with a lot of benefits. A data analyst has been asked to share all of these benefits with their team as part of a training exercise. One of the benefit statements the analyst provided to their team is incorrect.
Which statement about Query History is incorrect?
A data analyst has created a Query in Databricks SQL, and now they want to create two data visualizations from that Query and add both of those data visualizations to the same Databricks SQL Dashboard.
Which of the following steps will they need to take when creating and adding both data visualizations to the Databricks SQL Dashboard?
A data analysis team is working with the table_bronze SQL table as a source for one of its most complex projects. A stakeholder of the project notices that some of the downstream data is duplicative. The analysis team identifies table_bronze as the source of the duplication.
Which of the following queries can be used to deduplicate the data from table_bronze and write it to a new table table_silver?
A)
CREATE TABLE table_silver AS
SELECT DISTINCT *
FROM table_bronze;
B)
CREATE TABLE table_silver AS
INSERT *
FROM table_bronze;
C)
CREATE TABLE table_silver AS
MERGE DEDUPLICATE *
FROM table_bronze;
D)
INSERT INTO TABLE table_silver
SELECT * FROM table_bronze;
E)
INSERT OVERWRITE TABLE table_silver
SELECT * FROM table_bronze;
Which of the following should data analysts consider when working with personally identifiable information (PII) data?
How can a data analyst determine if query results were pulled from the cache?
Delta Lake stores table data as a series of data files, but it also stores a lot of other information.
Which of the following is stored alongside data files when using Delta Lake?
A data organization has a team of engineers developing data pipelines following the medallion architecture using Delta Live Tables. While the data analysis team working on a project is using gold-layer tables from these pipelines, they need to perform some additional processing of these tables prior to performing their analysis.
Which of the following terms is used to describe this type of work?
A data analyst has a managed table table_name in database database_name. They would now like to remove the table from the database and all of the data files associated with the table. The rest of the tables in the database must continue to exist.
Which of the following commands can the analyst use to complete the task without producing an error?
The stakeholders.customers table has 15 columns and 3,000 rows of data. The following command is run:
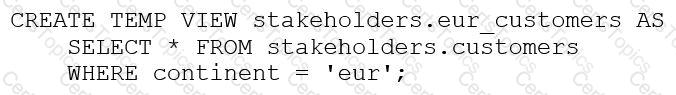
After runningSELECT * FROM stakeholders.eur_customers, 15 rows are returned. After the command executes completely, the user logs out of Databricks.
After logging back in two days later, what is the status of thestakeholders.eur_customersview?
A data analyst has been asked to produce a visualization that shows the flow of users through a website.
Which of the following is used for visualizing this type of flow?
A data analyst has created a Query in Databricks SQL, and now wants to create two data visualizations from that Query and add both of those data visualizations to the same Databricks SQL Dashboard.
Which step will the data analyst need to take when creating and adding both data visualizations to the Databricks SQL Dashboard?
Data professionals with varying responsibilities use the Databricks Lakehouse Platform Which role in the Databricks Lakehouse Platform use Databricks SQL as their primary service?
A data analyst wants to create a dashboard with three main sections: Development, Testing, and Production. They want all three sections on the same dashboard, but they want to clearly designate the sections using text on the dashboard.
Which of the following tools can the data analyst use to designate the Development, Testing, and Production sections using text?
A data analyst has been asked to use the below tablesales_tableto get the percentage rank of products within region by the sales:

The result of the query should look like this:

Which of the following queries will accomplish this task?
A)

B)

C)

D)
Consider the following two statements:
Statement 1:

Statement 2:
Which of the following describes how the result sets will differ for each statement when they are run in Databricks SQL?
Which of the following statements describes descriptive statistics?
Which location can be used to determine the owner of a managed table?
A data analyst has set up a SQL query to run every four hours on a SQL endpoint, but the SQL endpoint is taking too long to start up with each run.
Which of the following changes can the data analyst make to reduce the start-up time for the endpoint while managing costs?
A data engineering team has created a Structured Streaming pipeline that processes data in micro-batches and populates gold-level tables. The microbatches are triggered every 10 minutes.
A data analyst has created a dashboard based on this gold level data. The project stakeholders want to see the results in the dashboard updated within 10 minutes or less of new data becoming available within the gold-level tables.
What is the ability to ensure the streamed data is included in the dashboard at the standard requested by the project stakeholders?
Copyright © 2021-2026 CertsTopics. All Rights Reserved
